Mon 27 October 2025
| Modified: Thu 29 January 2026
Ostorlab’s AI Pentest Engine is built to behave like an expert penetration tester across both web and mobile applications. It combines deep reasoning with powerful tooling and an adversarial validation loop, so it can explore an application’s attack surface, identify risks, collect evidence, and either confirm or refute potential vulnerabilities.
Under the hood, the engine runs on the Ostorlab OXO Open-Source Agent/Scanner orchestrator, which separates concerns, manages concurrency, and scales horizontally.
This architecture composes specialized subagents (Executors) with powerful tools, ranging from simple probes to advanced crawlers, fuzzers, and taint engines, so the engine can execute actions that go well beyond what an LLM can reliably synthesize on demand.
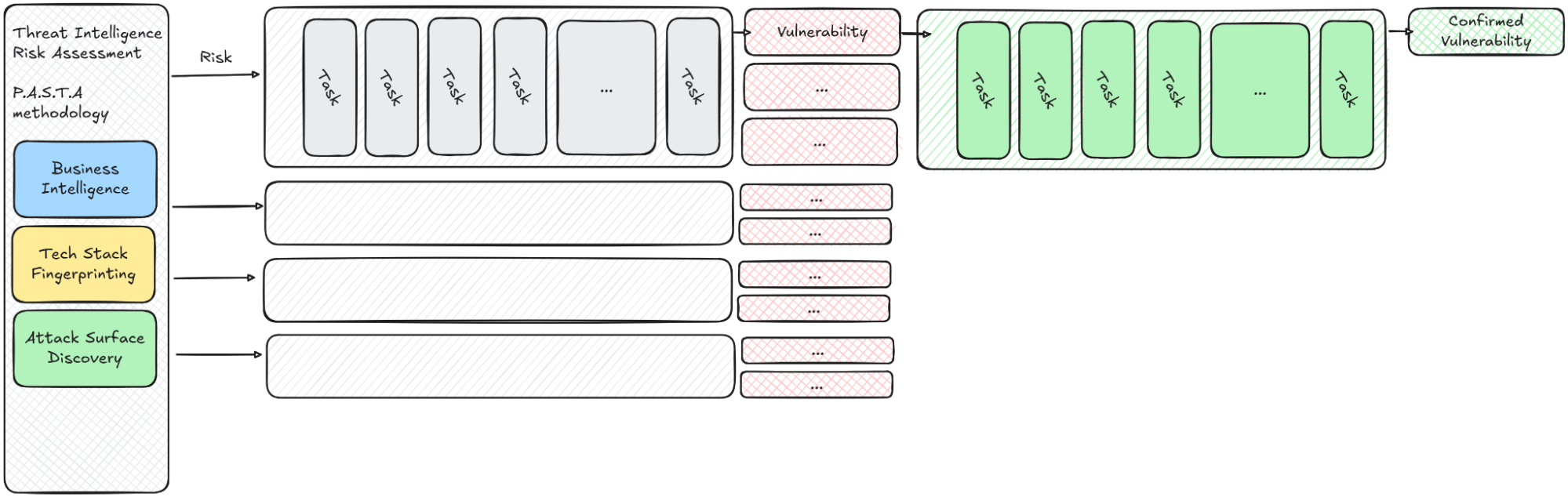
The engine’s workflow starts from threat intelligence with risk modeling using the P.A.S.T.A methodology, into iterative testing, followed by evidence capture, adversarial validation, and finally risk rating and reporting.
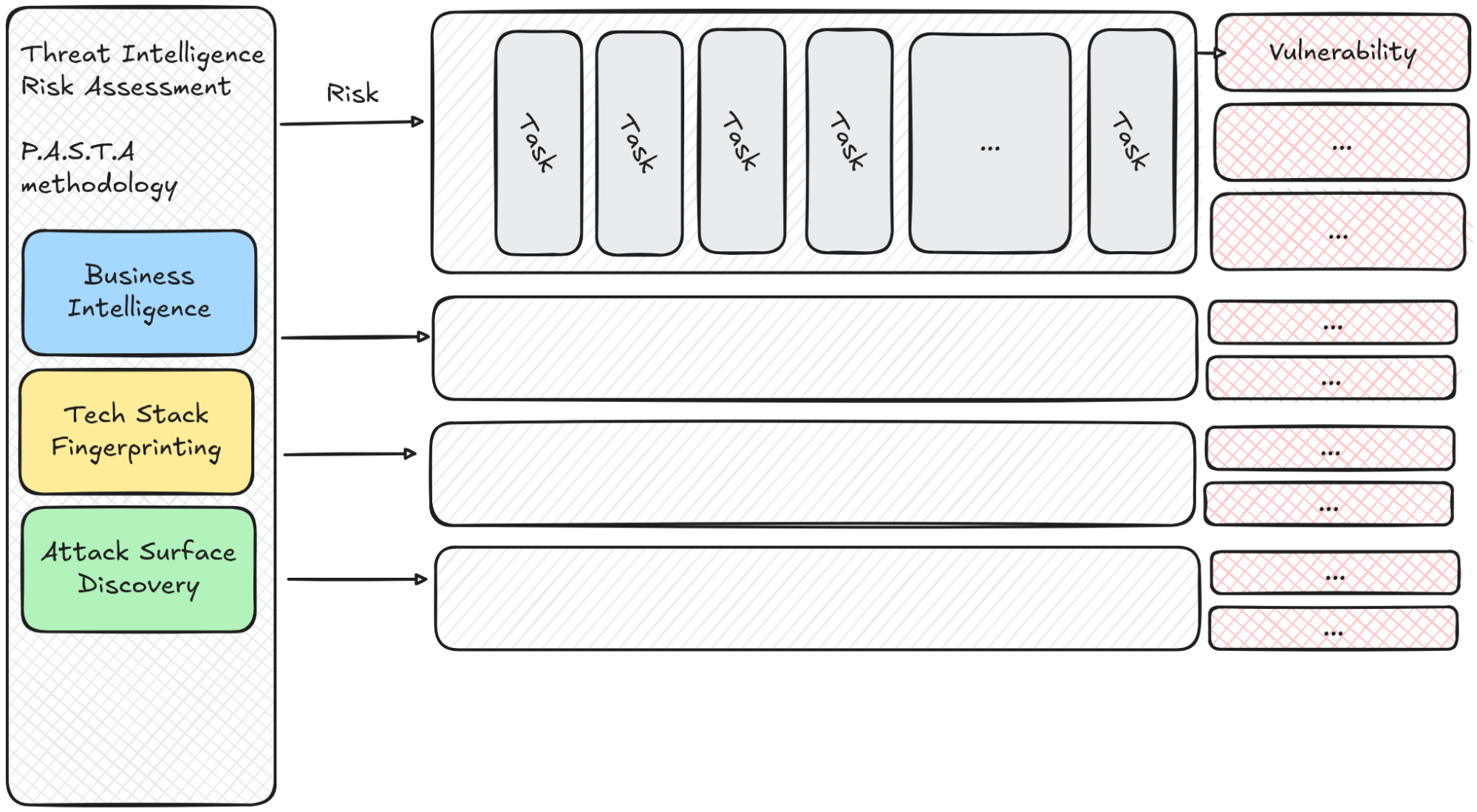
Ostorlab AI Pentest Engine: Architecture at a Glance
At the center is the orchestrator, the Ostorlab OXO Agent/Scanner, which schedules work and ensures fault-tolerant execution across subagents and tools. Above that sits the AI Reasoning Engine, which collects target information, decomposes it into risks and then performs parallel and iterative testing.
Surrounding these components is the tooling layer composed of a spectrum of tools that runs from simple yet versatile tools like curl and python to complex systems like a high-coverage crawler, a mobile monkey tester for UI flows, backend fuzzers, and taint-analysis engines.
During execution, the engine persists artifacts and summarized observations that can advance reasoning while avoiding bloat that degrades performance and accuracy and may lead to confusion.
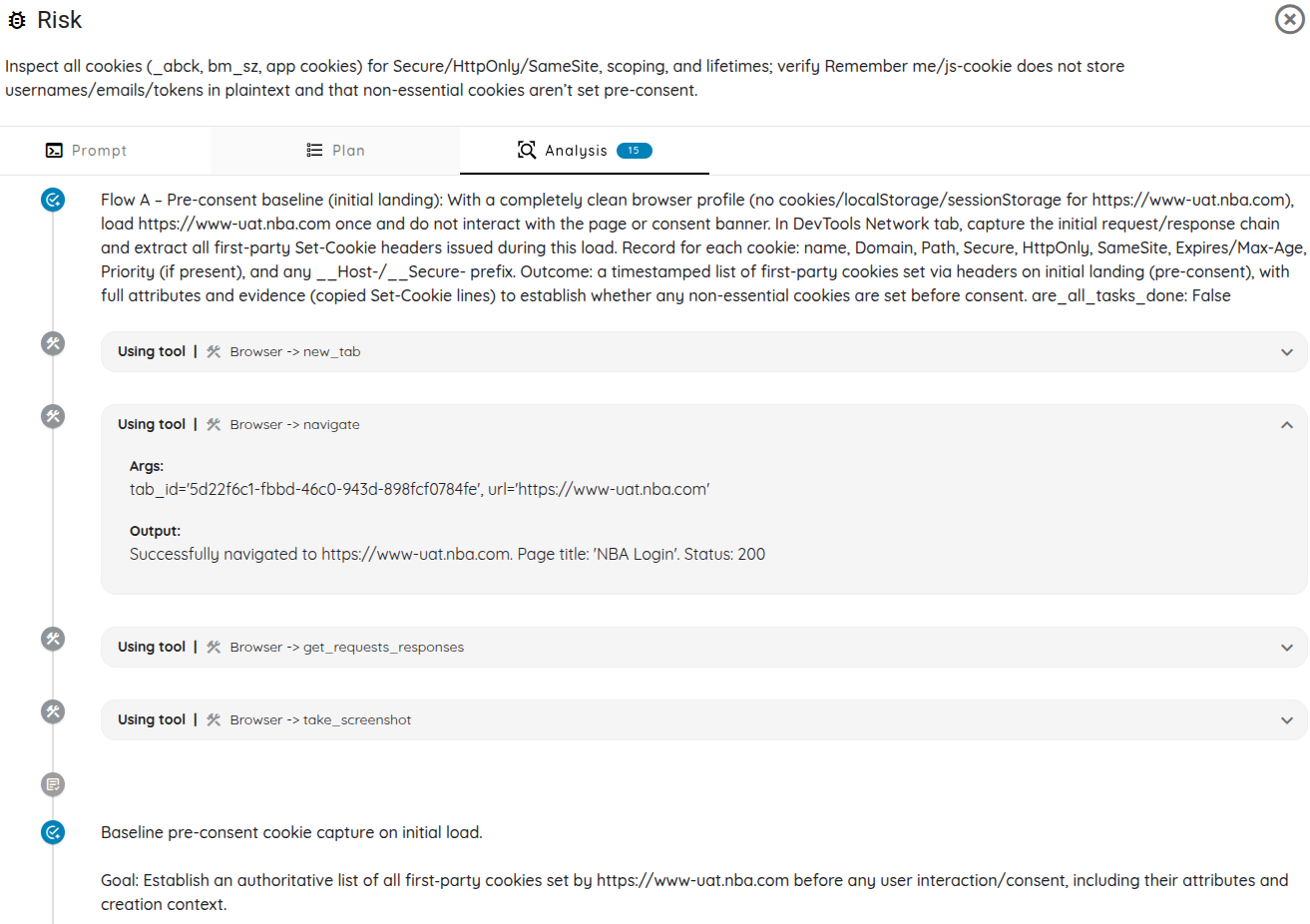
A typical “engagement” (scan) begins by ingesting a target and custom prompts. These are then used to gather threat intelligence to understand business context, technology stack, and attack surface. Next, the engine constructs a risk model and deduplicates overlapping hypotheses to reduce noise.
Iterative testing then proceeds via specialized subagents and tools, with evidence captured and assessed at each step. A dedicated adversarial validation pass independently re-examines findings to counter affirmative bias, and finally, the engine assigns a risk rating and produces a clear, actionable report.

Threat Intelligence and Scoping
A critical step is understanding what the application does and why it matters. The engine collects business context, product domain, roles, sensitive operations, and potential abuse cases, alongside the technical stack, third-party services, and deployment patterns. It also maps the attack surface, including APIs, endpoints, authentication flows, data stores, and mobile capabilities to frame testable, meaningful risks.

This stage is extensible as teams can enrich the engine with custom prompts, internal documentation, or source code, enabling application-specific risk modeling rather than one-size-fits-all checks. The outcome is a prioritized catalog of risks mapped to components and user flows; if a risk isn’t modeled here, it won’t be tested later, which makes the quality of this phase make-or-break for the entire pipeline.
First-Class Mobile Testing
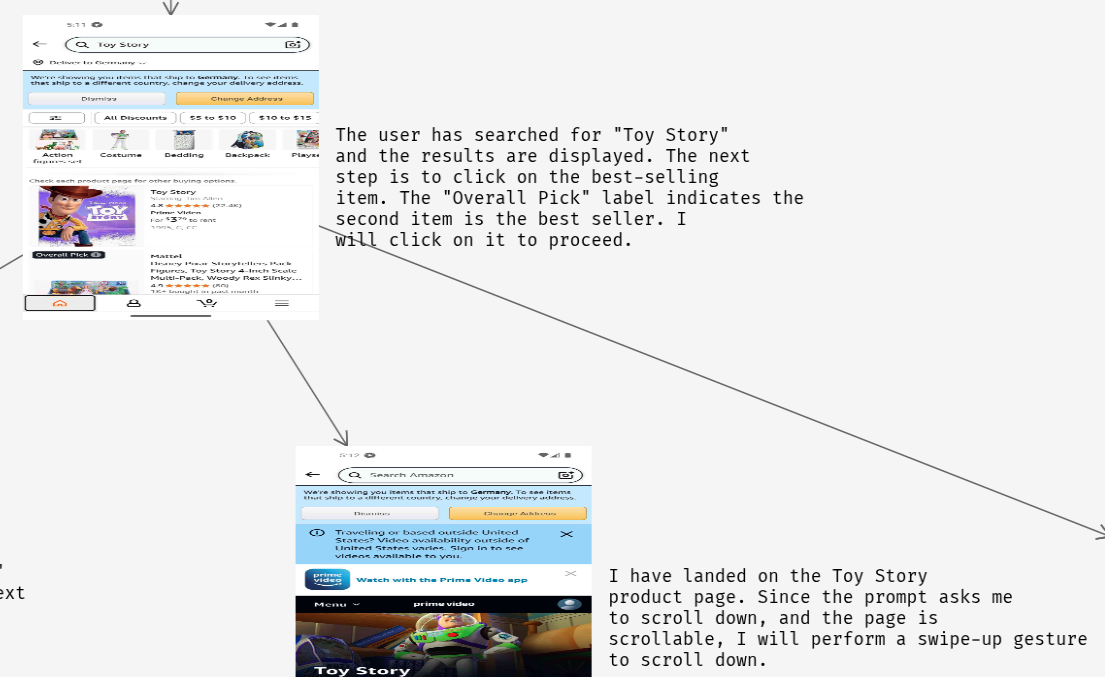
Mobile is not a bolt-on. The engine includes AI-Monkey Tester, a UI reasoning and automation system that navigates complex, platform-aware flows rather than tapping randomly. It can complete multi-step journeys, such as a checkout that requires a valid address, postal code, and even a CAPTCHA, while maintaining state and recording interactions for replay.
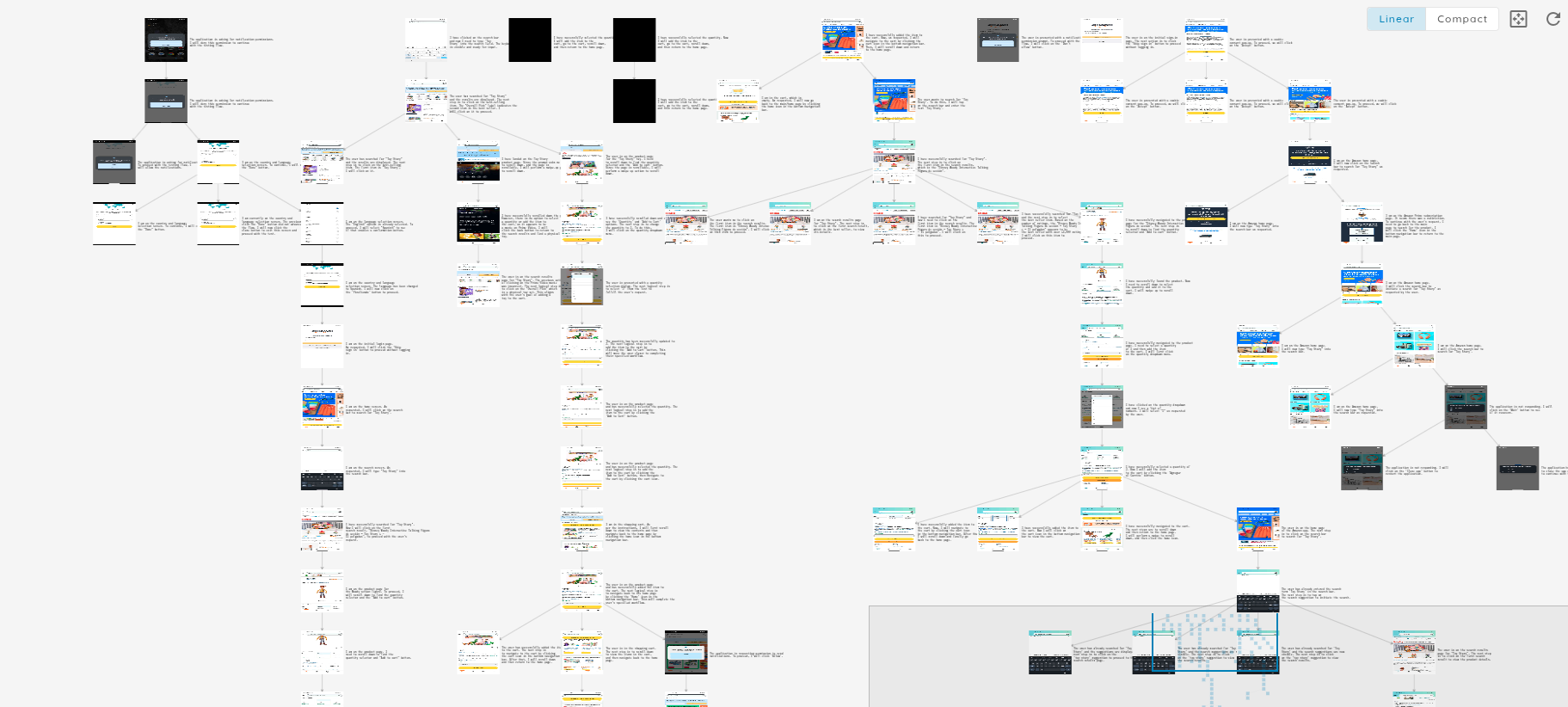
This approach surfaces logical and contextual issues that static analysis or naive automation would miss. It observes how the application behaves as a user moves through real-world scenarios.
To truly understand how an app behaves at runtime, the engine intercepts and modifies traffic, including bypassing TLS/SSL pinning where appropriate to observe API calls. It layers instrumentation across stacks like Java, Objective-C/Swift, C/C++, Flutter to hook behaviors and inspect data.
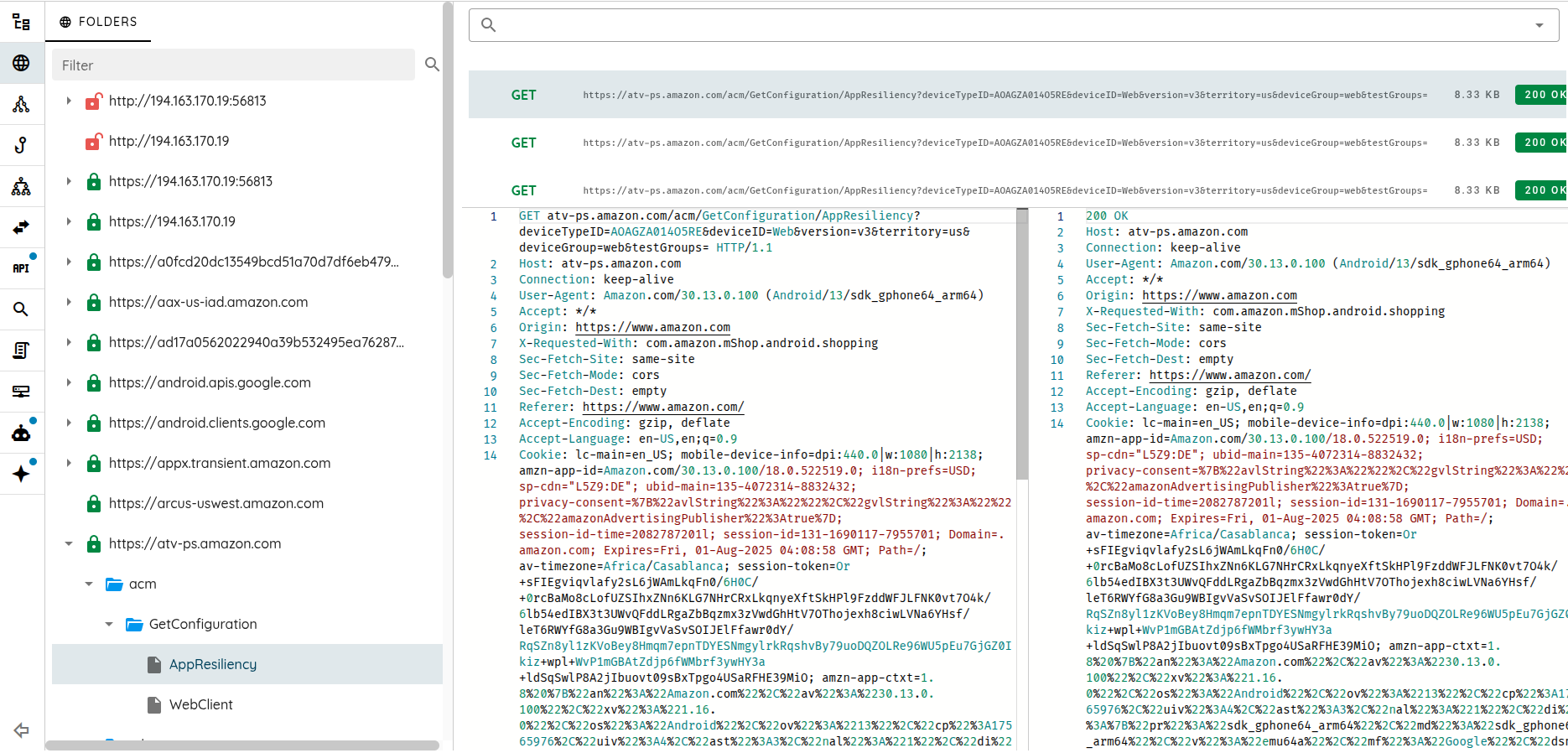
These capabilities allow the engine to see what the app is doing under the hood, not just what it claims to do. With controlled interception and instrumentation, it can explore, manipulate, and validate behavior that would otherwise be opaque.
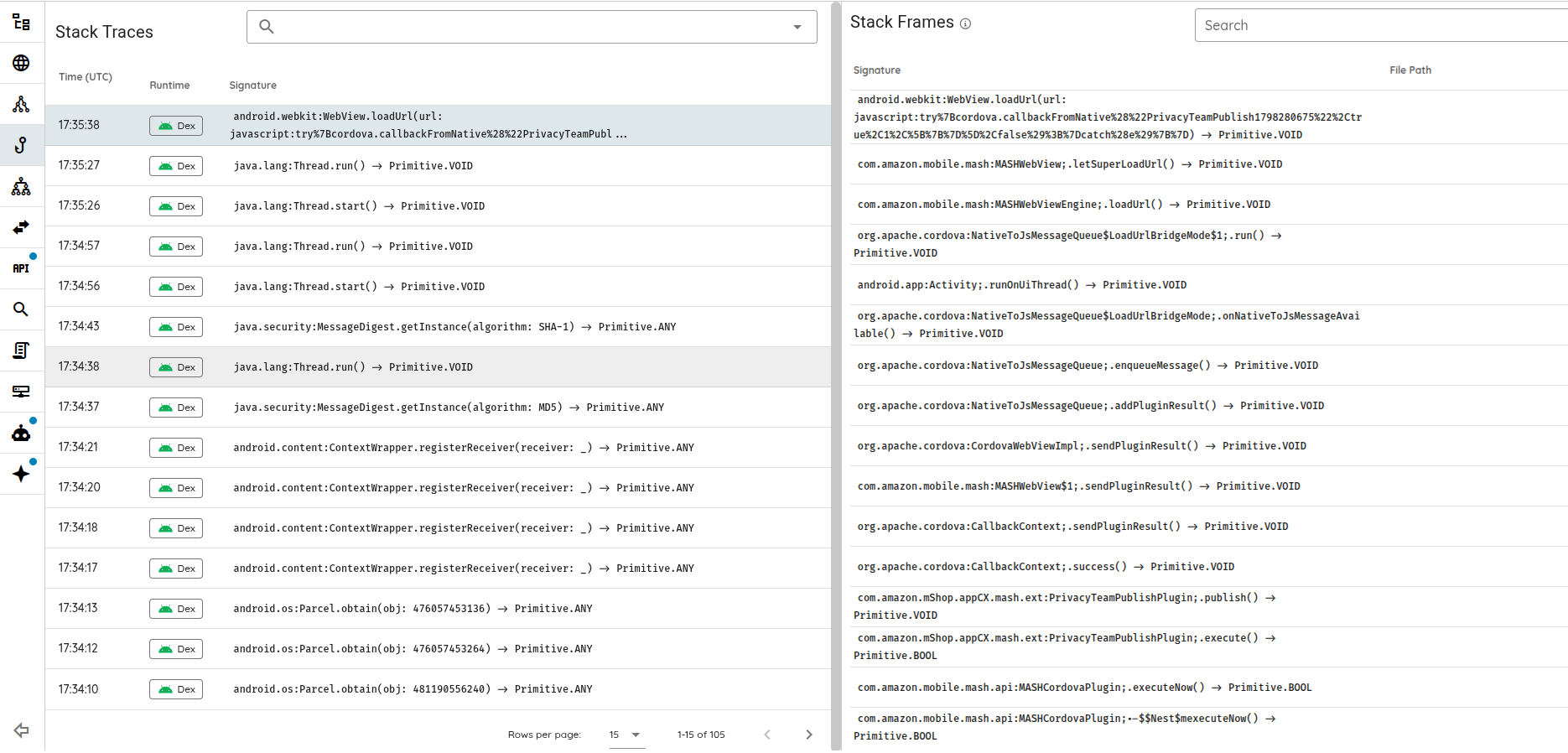
The engine balances simple probes with heavyweight analysis. On one end, simple tools like curl and a Python shell enable quick checks and scripted experiments. On the other hand, advanced systems, like high-coverage crawlers, the AI-Monkey Tester, fuzzers, and taint-analysis engines deliver the depth and performance needed for serious dynamic and flow-aware analysis.
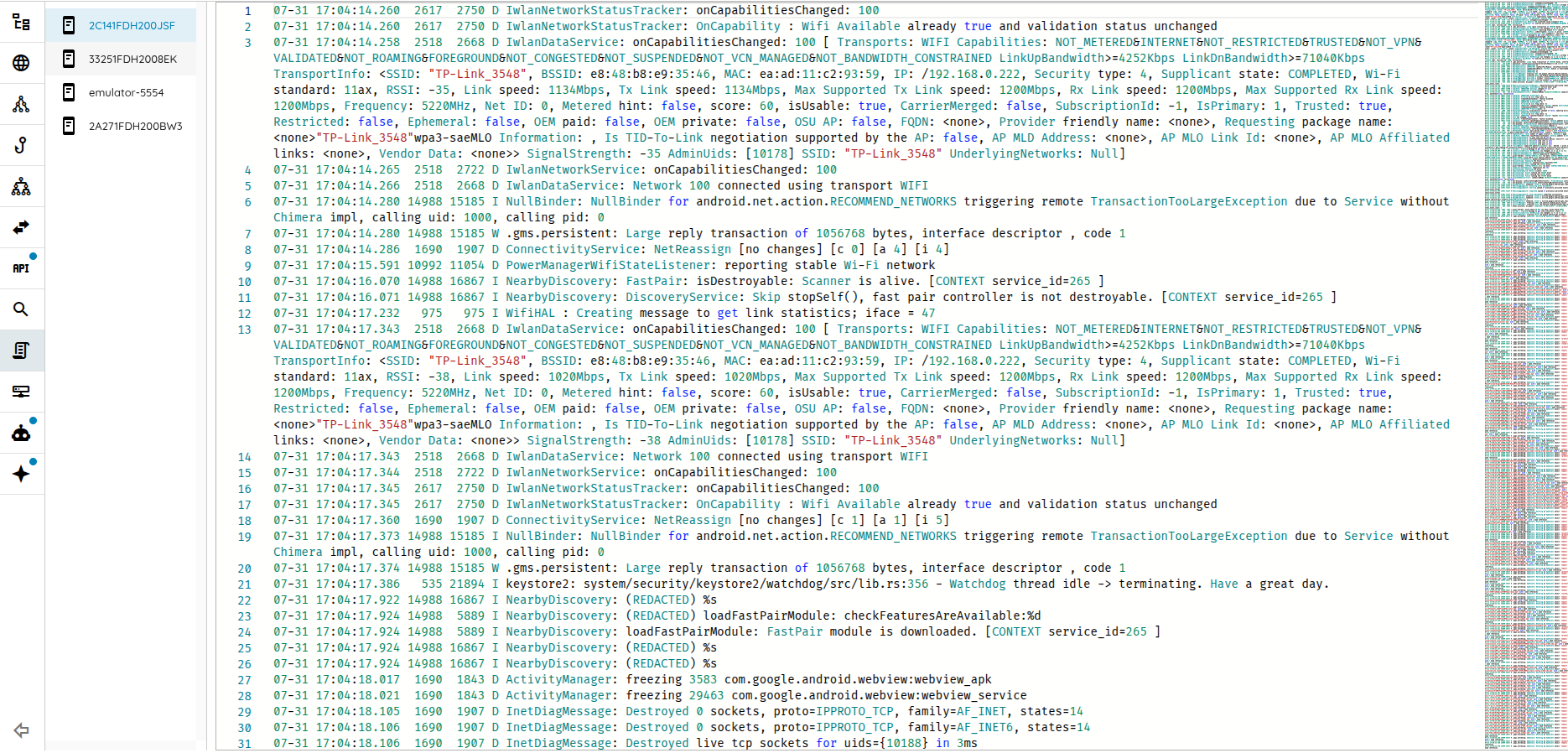
This matters because many high-value checks require specialized, performance-sensitive code that can span tens of thousands of lines. Expecting an LLM to generate and verify such systems on the fly is unrealistic. Instead, the engine composes proven, dedicated tools and lets the AI handle planning, orchestration, and interpretation.
Risk Modeling, Deduplication, and Rating
Risk generation is based on the threat modeling methodology PASTA and focuses on both generic vulnerabilities, like injection or XSS, and most importantly on business-specific issues that depend on the target context and user flows.
This disciplined approach provides clarity for security teams and developers. It makes it obvious what to fix first, why it matters, and how to reproduce and verify the issue.

Iterative Testing with Specialized Subagents
Subagents encode expertise through carefully crafted system prompts, task-specific guides, and curated toolsets. Small wording changes to the prompt can significantly affect reasoning behavior, so these prompts and guides are designed and tested with great care.
For each risk, the engine follows an execution loop: generate hypotheses, choose tools, run tests, evaluate evidence, and then refine or escalate to deeper tooling as needed.
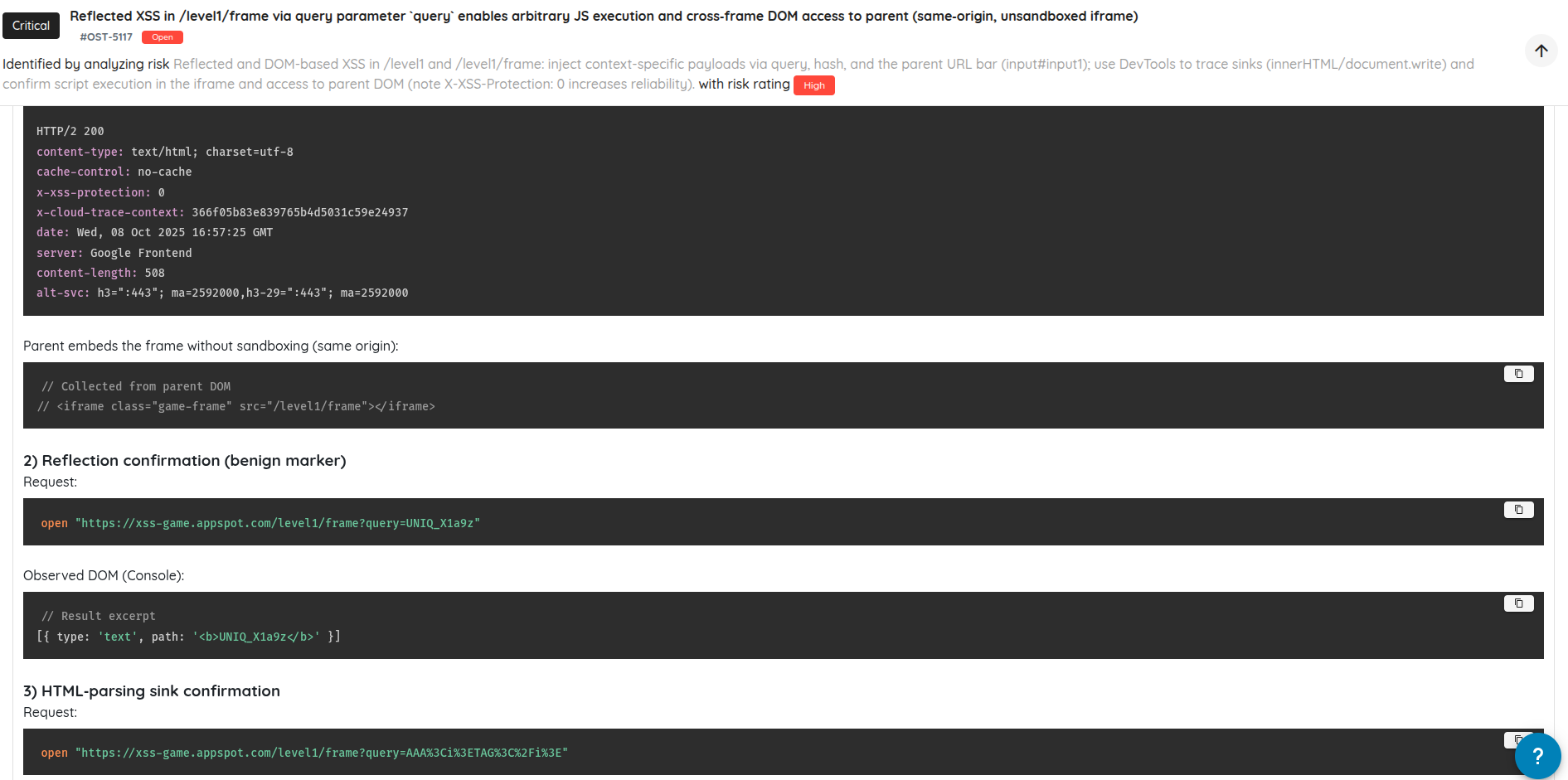
Memory management between tasks is carefully curated. The engine records just enough context to maintain continuity without drifting, ensuring a balance that preserves both having necessary information without bloating it with noise.
LLMs hallucinate, get confused, and can result in reported findings that can be misleading or incomplete. To counter this, each finding undergoes a second, independent validation using a “negative” or adversarial prompt designed to refute the claim. Where applicable, the same tools and subagents are reused to replicate or challenge the original result.
Outcomes fall into two buckets. Confirmed vulnerabilities are validated with supporting evidence and receive a confirmed risk rating (Critical, High, Medium, Low and Hardening). Findings that cannot be reproduced reliably are reported as “potential,” with clear caveats, reproduction gaps, or test limitations so teams can decide how to proceed.
Many of the most valuable issues are logical or contextual rather than templated CWE patterns. Fixed validators tend to miss these, especially when proprietary protocols, app-specific behaviors, or novel abuse paths are involved. Adaptive validation leverages evolving model capabilities and benefits from ongoing advances in reducing hallucinations and improving reasoning.
This flexibility is critical for real-world applications. As the landscape changes and as models improve the validation layer can adapt without discarding nuanced. For instance the quality of finding accuracy significantly increased with models like GPT-5. While other models like Gemini 2.5 Pro has shown improved reasoning capabilities to find complex bugs, it resulted as well in blatant hallucinations with results are invented.
A Concrete Example: Contextual Risk Beyond Common Vulns
Consider a dating app that exposes a “nearby matches” endpoint. By combining fake GPS inputs with repeated queries, an attacker might triangulate precise user locations and deanonymize individuals. The engine models this risk during threat intelligence, designs targeted tests using controlled location spoofing and response-pattern analysis, and then verifies exploitability by quantifying precision and effort required.
This is the kind of issue that slips past generic scanners. It depends on context, behavior, and intent.
Evidence, Reporting, and Outcomes
Throughout testing, the engine captures the right artifacts to enable reproduction and verification: HTTP requests and responses, UI interaction traces, instrumentation logs, and screenshots or recordings. Reports highlight clear reproduction steps, affected components, impact analysis, and pragmatic mitigation guidance, with potential findings explicitly labeled and explained.
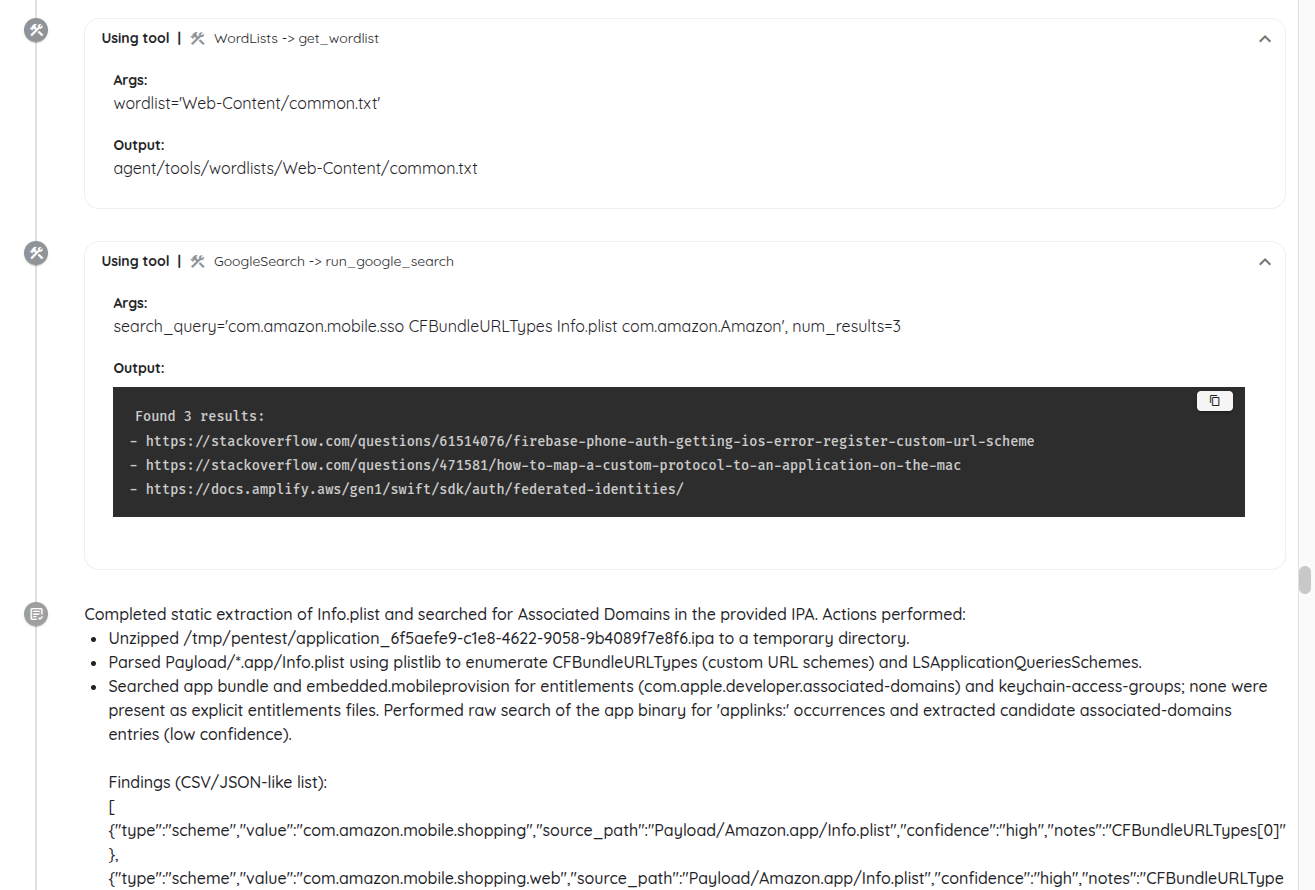
Each finding is linked back to its originating risk hypothesis and the tools or subagents that established—or refuted—it, giving teams confidence in both the process and the results.

Takeaways and What’s Next
The engine is capable of emulating a skilled human pentester by combining reasoning with targeted tooling and iterative, adversarial validation. Mobile testing is baked as a first-class, with powerful UI reasoning for complex flows and deep runtime instrumentation.
Threat intelligence quality plays a decisive role because the pipeline tests only the risks it models.
Moving forward, ensuring subagent-task fit is an active area of improvement. A generalist subagent can underperform on niche or domain-specific risks, so better auto-selection and specialization are critical. On-demand external research is another trade-off, while it can enrich context, it may also introduce both latency and higher hallucination risk.
To test the AI Engine, you can join our waitlist here.
Table of Contents
- Ostorlab AI Pentest Engine: Architecture at a Glance
- Threat Intelligence and Scoping
- First-Class Mobile Testing
- Risk Modeling, Deduplication, and Rating
- Iterative Testing with Specialized Subagents
- A Concrete Example: Contextual Risk Beyond Common Vulns
- Evidence, Reporting, and Outcomes
- Takeaways and What’s Next