Mon 26 October 2020
Overview
The Autonomous Cars Industry defines 6 levels of driverless vehicles:
- L0 - No automation
- L1 - Driver Assistance
- L2 - Partial Automation
- L3 - Conditional Automation
- L4 - High Automation
- L5 - Full Automation.
While the world of SRE (Site Reliability Engineering) has already adopted the term Autonomous System to refer to the
judicious application of automation, the word Autonomous Security is not widely used by the Security industry.
For SRE, automation is a force multiplier, not a panacea. Of course, just multiplying force does not naturally change the accuracy of where that force is applied: doing automation thoughtlessly can create as many problems as it solves. Therefore, while we believe that software-based automation is superior to manual operation in most circumstances, better than either option is a higher-level system design requiring neither of them—an autonomous system. Or to put it another way, the value of automation comes from both what it does and its judicious application.
While no one will disagree that Security Automation is critical to scale security ops within any organization. The size, diversity, and complexity in which we are operating make the current approach of having humans and manual processes to address the volume vulnerabilities and incidents not so scalable. Scaling teams will eventually be limited by how many people we can hire, scaling processes will eventually cripple an organization's productivity.
The goal of Autonomous Security is to automate the decision process. In the context of vulnerability scanning, for instance, this
might take the form of quarantining a vulnerable machine, setting up a firewall rule or deploying a patch, in the
context of incident response, this might take the form dumping memory for forensic analysis and reducing access to critical systems.
Achieving this high degree of automation cannot be done without effective technology and a feedback loop to measure what works, what does not and detect what is missing.
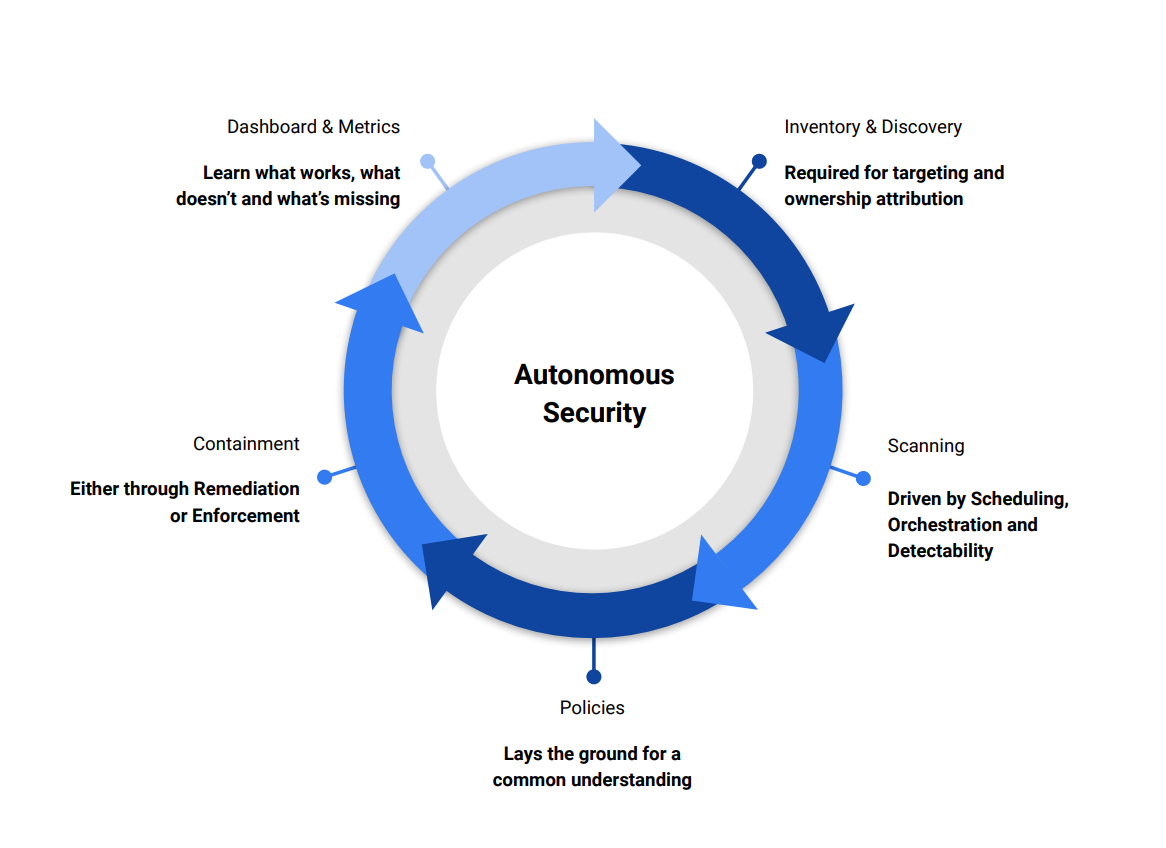
The following article coins the term Autonomous Security in the context
of Security Scanning and outlines the required technological blocks and policies. The end goal is to automate
containment and use a feedback loop to address missing parts and blind spots.

The document defines 5 tiers to reflect the different maturity levels. In the next sections, we will define each block
and how its maturity level can be enhanced while achieving the goal of a fully Autonomous System.
| Concept | T0 | T1 | T2 | T3 | T4 |
|---|---|---|---|---|---|
| Inventory & Discovery | No Inventory | Manual Inventory | Partially Automated Inventory | Fully Automated Inventory | Fully Automated Inventory with discovery |
| Policy | No Policy | Patching Policy | Patching + Black Swan Policy | Patching + Black Swan + Freshness Policy | Patching + Black Swan + Freshness + Enforcement Policy |
| Scanning | Occasional Scanning | Low frequency Scheduled Scans | Scheduled Scans | Scheduled Scans and Continuous Event-based Monitoring | Scheduled Scans, Continuous Event-based Monitoring with historical tracking |
| Containment | Manual Remediation | Manual | Semi-automated | Automated | Automated + Enforcement |
| D&M | No Dashboard | Scan Dashboard | Coverage, Scan and Fixes | Coverage, Scan, Fixes and Exec | Coverage, Scan, Fixes, Devs, Ops and Exec |
1. Inventory & Discovery
Inventory consists of listing assets and collecting useful metadata like ownership, usage (Prod vs. Dev), and targeting information, for instance listing all the desktop machines within your organization and collecting metadata like MAC address, IP address, and employee owner.
Inventory is used for security scanning to schedules scans, assign vulnerabilities for fixes, present an aggregated view of the security of an environment and drive strategic remediation.
Inventory is difficult to maintain when it is purely security focused and is better if it is not operated by the security team. Inventory maintenance is challenge both; from a technical and a process perspective. In most cases and environments we are faced with the need to keep inventory of assets with different and contradicting requirements, such as highly volatile vs. immutable assets, low volume with frequent changes vs. high volumes with rare changes, or ambiguous vs. hierarchical ownership. Hence, building and maintaining an infrastructure that copes with all of these requirements is a very challenging problem.
For example scanning desktop machines vs. database servers, desktops routinely change IP addresses and have a single owner, while a database server rarely changes an IP address, and the services they run; have separate owners.
Moreover, Inventory can benefit a wide range of usages, like tracking consumption (financial), monitoring deployments (production), hence, making it is easier to maintain if driven by production as it is usually the best way to keep it up to date.
As a case in point, the newly open-sourced project
Backstageby Spotify Backstage. According to the team behind the project, because theBackstageprovides the tools to create and monitor deployments, it has naturally became the source of truth of their inventory.
While an up-to-date inventory is ideal, it is practically not achievable due to blind spots caused by human interaction or technological limitations.
As it is taxing to determine blind spots, Inventory should always be augmented with an external discovery component that tries to locate respective blind spots. Discovery should continuously attempt to find the loopholes that remain uncovered.
The discovery system is not limited to technical tools, like domain name brute forcing, but can also resort to other means, like tracking payment done with enterprise credit card to find non listed cloud projects for instance.
2. Scanning
Scanning has 3 dimensions, namely scheduling, orchestration and detection that are as follows:
2.1 Scheduling
Scheduling addresses the question of when to scan; it is either time based or event based. Time-based like for instance once a day. Event based like at each submit or every time a new container is created. The scheduling is driven by the asset lifetime and the vulnerability report lifetime.
Not all assets are equal when it comes to scheduling, for instance scanning a public website requires a continuous time based rules, while containers for instance require an event based to scan at creation and the detection of a new CVE affecting one of the container dependencies.
Event-based scanning is always preferred over time based scans as we narrow the window of when things can get wrong. It is unfortunately not always possible. Take for instance black box scanning of a website, without any measure of how things are changing or evolving, the only option we have is a time-based approach.
Current time-based approach can be drastically enhanced by avoiding full re-scans and building on previous scan results and coverage. Take for instance scanning a website, instead of doing full crawl with every scan, scanner can use previous crawls to speed up scans, detect changes and focus tests.
A fully Autonomous Security pipeline doesn't need to hammer an asset with continuous scans, but can take a smarter
approach. If an asset is a static website and it hasn't changed in the last 6 months, the system should be able to
lower the frequency of scans.
2.2 Orchestration
Orchestration defines how to handle the lifecycle of a scan, like what to do in the case of a failure, whom to notify during the different phases of a scan, should a set of extra resolution steps or notification get triggered, should a duplicate dedicated environment get created for scanning.
With service mesh type architecture (e.g. Istio), it is possible to create a
testing gardenby duplicating a set of services for scanning, route scanning traffic to the new mesh based on a header value for instance and apply quota to access shared components like a database or a message queue.
Orchestration is typically critical for compliance regimes, like PCI-DSS or FedRamp. A fully Autonomous Security pipeline
can define a set a hooks to trigger business oriented logic, like notify certain people, update certain dashboards,
generate certain reports, etc.
2.3 Detection
Detection is usually what most people think of when we talk about security scanning. As important as it is, it is only one cog in a large machinery.
Proper detection must reduces false positives and negatives and take context to rate severity. Finding the correct balance the suits the size of an organization and the severity of an environment is an important balance.
Creating a map of the type of assets owned by an organization and creating a coverage map is helpful to identify missing capabilities, an simplified map could be as simple as:
* Network:
* IPv4: CHECK
* IPv6: MISSING
* Web:
* Known Vulnz: CHECK
* non-SPA: CHECK
* SPA: MISSING
* Authenticated: MISSING
* Mobile:
* Android: CHECK
* iOS: CHECK
* Mobile Backend: CHECK
* Cloud:
* VM: MISSING
* Containers: CHECK
* Serverless: MISSING
...
or as complex as :
* Web:
* SQL Injection:
* Postgrs:
* WHERE Clause: CHECK
* FROM Clause: MISSING
* ORDER Clause: LIMITED
While detection is a VERY large topic, a common complaint in this space is that security vendors often over-promise and under-delivered space. This is good resource on why the security industry is failing due to ineffective technology
All security solutions can be split into 2 technological pieces, an Analysis Engine and set of Rules. The engine is typically
what takes a program, a website, an IP and performs a set transformations or interactions.
Example of Analysis Engines:
- Dependency fingerprint engine: Find dependencies and 3rd party components.
- Taint Engine: Generate object-oriented graph taint to find link between sources and sinks.
- Dynamic Engine: Collect stack traces, methods and parameters.
- Fuzz Engine: Injects inputs and collects data flow and crash reports.
The engine outputs are then used by the Rules to detect vulnerable behavior. Rules are typically something like:
- If application name is
libjpegversion <2.0.1and has BMP enabled, then vulnerable to memory corruption. - If encryption API used with
ECBmode, then vulnerable to insecure encryption mode.
Ruleshave always been handcrafted by experts and usually use the results of a singleAnalysis Engine. Because of the economics and cost of creatingRules, detecting unlikely vulnerabilities in not so common frameworks, even with severe consequences, is rarely done.
3 Policies
Policies are the guiding principles, they set the framework to take decisions. Policies, when vetted by the correct channels (CTO, CISO ...), help organisations take timely actions and reduce the need for escalations and back-and-forth discussions.
The traditional policy is the patching policy. It defines when a vulnerability is to be fixed, depending on its severity. For example, high severity issues are to be fixed within 1 month. If they don't, vulnerable assets can be enforced (see section 4) or escalated (see section 5).
You will surprised about how having a dashboard with out-of-SLO for instance, show to execs can help expedite fixes.
This patching policy is not sufficient as it is reactive to security issues and is, by definition, always late. A great addition is a freshness policy that requires software, dependencies, and an application to be no older than x months. Black Swan Policy is also anther great example that defines what to do in the case of highly severe vulnerabilities requiring several hands-on-deck from multiple teams.
Policies are essential, not only from a security perspective, but also from an operational perspective. They keep production healthy and avoid technical and production debt to accumulate.
Many organization share horror stories about some production-critical application that no one knows about how to build or deploy and, it has been serving production for years.
To achieve a fully Autonmous Security system, an enforcement policy is required to define how automated enforcement
can operate, does it require a human in the loop or on the loop, how break glass can be done and what systems are eligible.
Human-in-the-loop or HITL is defined as a model that requires human interaction. Human-on-the-loop or HOnTL is defined as a model that is under the oversight of a human operator who overrides actions. Human-out-the-loop or HOutTL is defined as a model that doesn't have any human interaction or oversight.
4. Containment: Remediation & Enforcement
Remediation is the most underrated and, paradoxically, the most critical block. Containment is what helps in fixing vulnerabilities or removing them.
Remediation is very challenging to get right. It is often a people problem first and gets difficult from trying to find right owner to get fixed, passing by having the proper incentives to get stuff fixed, finding the proper communication channel to report and track fixes, to finally having a way to verify that a vulnerability is properly fixed.
The Cloud offers great tooling to help with the qualification of fixes without impacting production workflow, with tools like Terraform to duplicate full projects, or service meshes like Istio to do canary deployment, are great for helping solve these problems.
Enforcement is the pinnacle of an Autonomous Security system, it helps preventing vulnerabilities
from slowly crawling into your system and is a great incentive to have developers and ops team
expedite fixes.
Enforcement should however account for the importance of making production reliable first and offering verifiable and traceable means to break glass when required. Enforcement can't be done without executive buy in and is better to start small, applying it to internet facing experimental systems, then internal systems up non critical production systems.
Enforcement can start with a human in the loop, green lighting enforcements and then passing by a human on loop, simply reviewing already taken actions.
Cloud offers tools to enforce secure deployment and recover from compromises, using tools like TUF and Notary.
5. Dashboards & Metrics
Dashboard and Metrics are critical part of an autonomous security system. They measure the health of a system, serve
a measurable way to compute return on investments and can help drive strategic actions with informed and data
backed decisions.
Dashboards help provide the right people with the right amount of information to take informed decisions
and prioritize actions. Having the capacity to understand your posture, how thing are improving (or not) and
quantitatively measure where things are missing is what is often missing in security.
Dashboards are partly driven by Metrics help identify trends, measure and prevent slow deterioration as well as
measure progress and return on investment.
organization wide dashboards that lists for instance the number of vulnerabilities by business units or teams are effective at enticing action. You will be surprised how no-one wants to be at the bottom of the chart and how leaderboards can drive a healthy competition.
Dashboard must be tailored for each user in a way that helps in making actionable decisions. For instance, security teams dashboard will for instance focus on severity and volume of vulnerabilities, C-level execs dashboard will focus on global health, business organization status and most urgent issues, developers dashboard will focus on code they own or work on.
Dashboard must provide a useful view to draw data backed conclusions and take informed actions.
What's next?
Ostorlab has been created to provide the tools to ease the integration of an Autonomous Security solution
within any organization. This starts by integrating with specialized stores and inventory APIs, providing capable technical discovery tools
(like Android and iOS store for mobile applications), focusing on the detection of high severity vulnerabilities with high confidence
(like outdated dependencies, secret leakage) and ease the creation of monitoring rules.
To stay informed about the latest updates, subscribe our monthly newsletter.
Tags:
security