Tue 24 March 2026
If Article 2 was about making DORA compliance feel like normal release governance, this one is about the next practical question mobile teams always get asked:
“What happens when something breaks?”
In BFSI mobile, that question is rarely theoretical. A dependency degrades, a provider has a bad day, a configuration change ripples the wrong way, and suddenly customers cannot log in or approve a payment. The goal of operational resilience is not to pretend these things never happen. It is to make sure you have rehearsed the failure modes that matter most, and that you can show what you did and what you learned.
This article gives you a simple drill library focused on mobile critical journeys. It is designed to be easy to run, easy to evidence, and easy to improve over time, without turning your team into a full-time exercise committee.
How to use this article
If you want the simplest way to get value, pick four drills from the library below and start there. Run one drill at a time against one journey, and keep the output consistent. Use the drill report template in Step 3, and keep follow-ups small and concrete. Before you begin, make sure everyone agrees on what you’re actually trying to keep resilient.
What “operational resilience” means for mobile teams
For mobile, resilience is best measured as “can a customer complete a critical journey safely.” Not “is the system up.” Not “did monitoring fire.” Journeys keep you honest because they reflect what users experience.
In BFSI mobile, the critical journeys are predictable:
- Login
- Step-up authentication, such as OTP or push approvals
- Account recovery
- Payments and transfers
When these journeys degrade, customers feel it immediately. That is why a mobile-first operational resilience program starts with journeys, then works backwards to dependencies.
Let’s pick the journeys, then map the dependencies, because drills are much easier when everyone agrees what is connected to what.
Step 1: Pick your critical journeys, then list their dependencies
Keep it simple. Start with three to five journeys. Most teams do not need more than that at first.
Recommended BFSI mobile journey set
- Login
- Step-up authentication, OTP and push approvals
- Account recovery
- Payments and transfers
- Onboarding and KYC, if it exists in your app
For each journey, document dependencies
You do not need a perfect diagram. A short list is enough.
Example dependency list for login:
- Identity provider and token service
- Backend API gateway
- Risk or fraud decisioning, if used at login
- Remote config or feature flags that can change auth behavior
- Mobile network layer configuration, including certificate pinning if used
- Observability and telemetry pipeline
This dependency list is what turns “resilience” into something you can test.
Now we can run drills that match real failure modes, instead of generic chaos for the sake of chaos.
Step 2: The drill library, the scenarios that matter most in BFSI mobile
Below are drills you can run without a huge setup. Each one is tied to a critical journey and a dependency pattern that causes real customer impact in BFSI. Start with three or four, run them, write down what surprised you, then expand. You are not trying to become a chaos engineering company. You are trying to make the most common failure modes boring.
A simple way to keep these drills consistent is to answer the same five questions every time: what did we simulate, how did we simulate it safely, what should the app do, what should the team be able to see and decide, and what evidence do we keep.
Quick start: if you only run four drills
If you only run four drills to begin with, this set covers a lot of BFSI mobile reality:
- Identity provider degradation
- OTP latency and delivery failure
- API gateway, WAF, or rate limiting blocks legitimate mobile traffic
- Remote config or feature flag mistake
| Drill | Journey impacted | What breaks | What “good” looks like | Evidence to capture |
|---|---|---|---|---|
| 1. Identity provider degradation | Login, token refresh | High auth latency, intermittent 5xx, refresh failures, session bootstrap failures | Safe retries with backoff, no retry storms; clean session state; clear error UX; quick version-scoped impact assessment | Auth latency and error dashboards; version-scoped impact note; decision log of mitigations tested |
| 2. OTP latency and delivery failure | Step-up authentication | Delayed or missing OTP, resend loops, throttling, correlation timeouts | Enforced resend limits and cooldown; no user dead-ends; safe messaging; clear operational fallback choice | OTP success rate and latency snapshot; capture of user experience states; follow-up change notes to resend/UI policy |
| 3. Push approval disruption | Step-up authentication, approvals | Push delays/outage, token invalidation, late approvals after timeout | Clean timeouts; no stuck approvals; consistent state across retries; clear recovery path | Push delivery metrics; delayed approval timeline snapshot; runbook updates for support/escalation |
| 4. API gateway, WAF, or rate limiting blocks mobile traffic | Login, payments | WAF rule misfire, strict rate limits, partial API gateway degradation, endpoint-specific blocks | Stable handling of 4xx/5xx; bounded retries; no load amplification; safe payment retry behavior | Config change log snippet; error-rate before/after rollback; client behavior note for 429/403 |
| 5. Certificate rotation and pinning failure rehearsal | All networked journeys | Cert chain issues, pin set mismatch, trust failures, device time skew | Predictable failure state; rehearsed recovery; no insecure “turn it off” workarounds | Runbook excerpt and improvements; impact scoped by app version; key lessons for rotation process |
| 6. Remote config or feature flag mistake | Login, payments, startup stability | Bad config rollout, config service outage, stale or inconsistent flags | Safe defaults; guardrails against bad combos; stable startup; fast rollback that can be verified | Config audit trail snapshot; metrics before/after rollback; follow-up improvements to defaults/guardrails |
| 7. Fraud or risk decisioning misconfiguration | Login, step-up, payments | False positives, lockouts, unexpected step-up spikes, inconsistent risk outcomes | Consistent handling; safe messaging; clear next step for user; coordinated rollback and recovery measurement | Risk decision metrics snapshot; support guidance update if needed; decision log for policy changes and rollback |
| 8. Third-party dependency incident affecting a journey | Payments, onboarding/KYC, risk scoring | Provider errors/latency, malformed responses, degraded dependency behavior | Safe degradation; consistent state; no repeated amplification calls; clear fallback decision | Provider error/latency snapshot; summary of fallback decision; monitoring/runbook improvements added |
Drills are only useful if you capture the right evidence; they become a calendar event that disappears into chat history.
Step 3: What each drill should produce, the evidence that actually helps
Keep drill output lightweight and consistent. You want something that helps engineering improve, helps decision makers understand risk, and supports the evidence you will want later.
The minimal drill report template
Use the same template for every drill.
| Drill Report | Details |
|---|---|
| Drill Summary | Journey tested • Scenario simulated • Environment • Participants (roles, not names) |
| Key Moments | Start time • Detection time • Containment actions & time • Recovery time |
| Impact | Customer experience • Affected app versions (if relevant) • Regional or provider-specific notes |
| Decisions | What was changed, by whom, and why • What was not changed and why |
| Outcomes | What worked well • What was confusing or slow • Missing monitoring/telemetry |
| Follow-ups | 1–3 concrete improvements • Owner for each improvement • Verification plan for improvements |
This is enough evidence to be useful without becoming paperwork.
Now the most important part, turning drill lessons into release controls, so the same issue does not surprise you again.
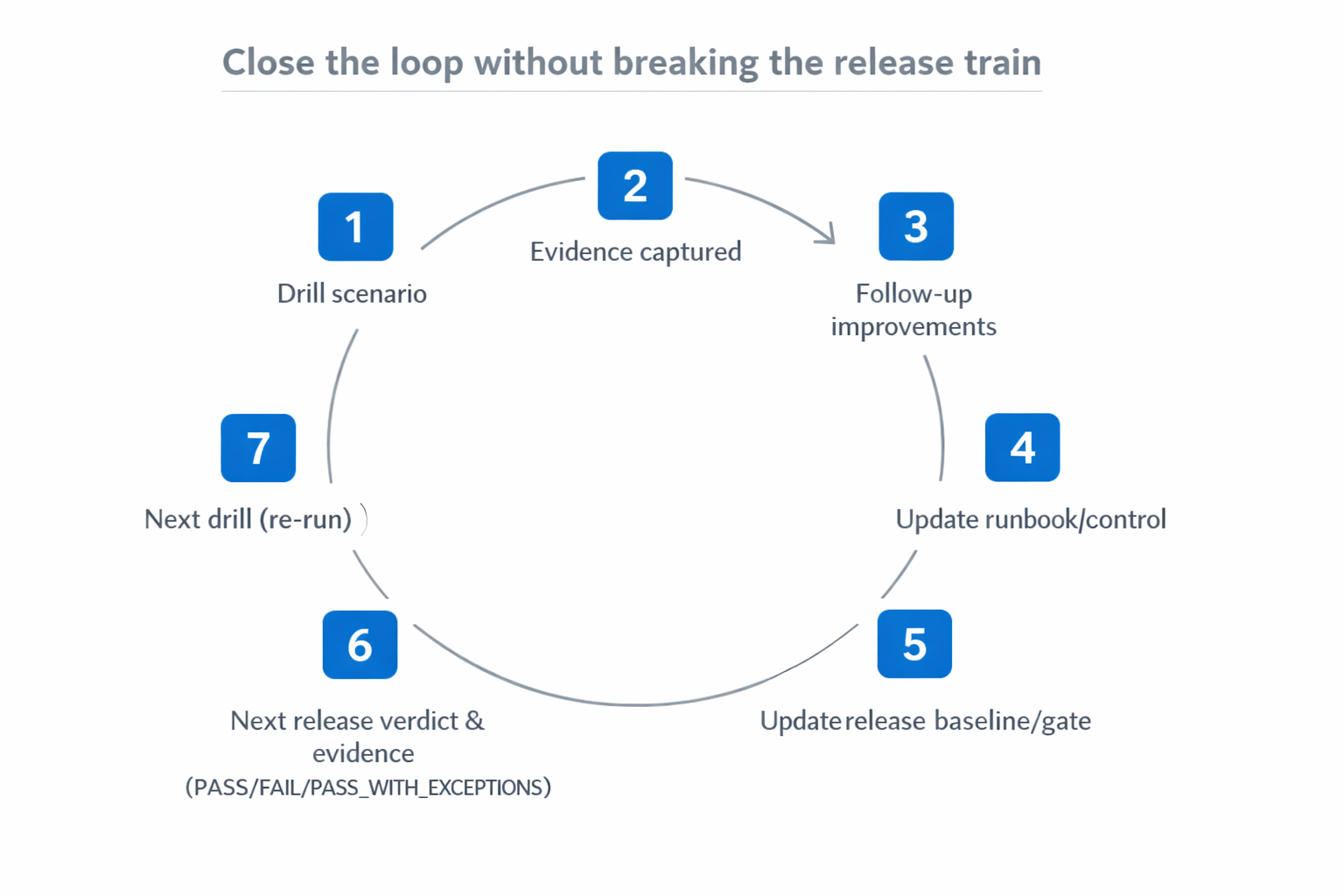
Step 4: Close the loop, drills should change release controls
This is where resilience work becomes part of your release program, instead of a parallel activity.
After every drill, ask two questions:
- What would have prevented this issue, or reduced impact, before release?
- What should we add to our release baseline or runbooks so we do better next time?
Examples of “drill to control” improvements:
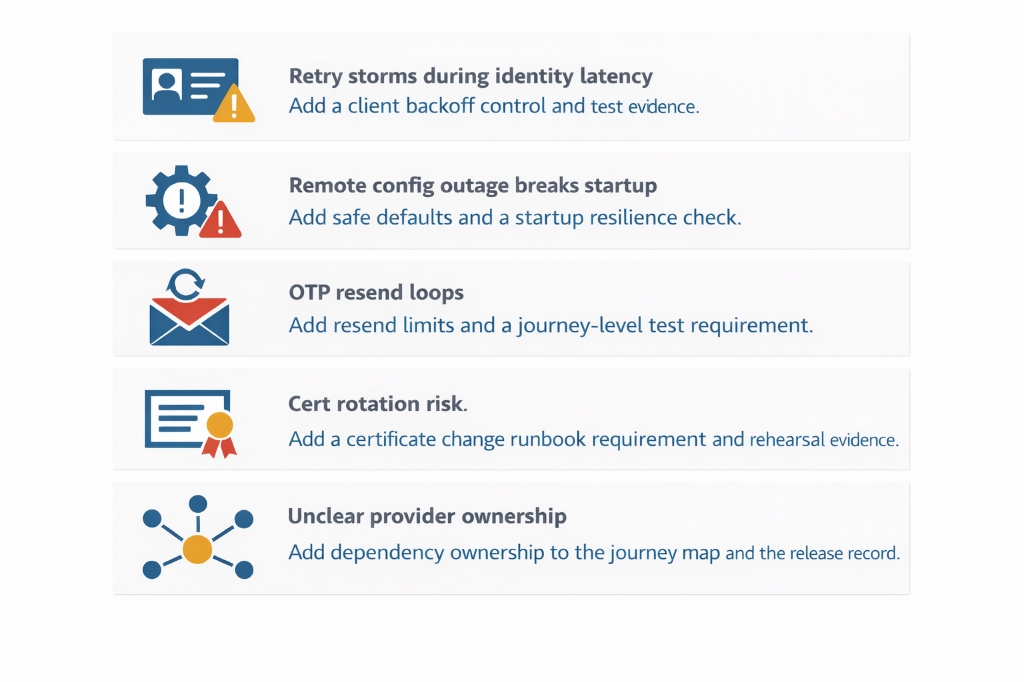
This is also where Article 2 and Article 3 connect. The release baseline should include a small set of resilience readiness controls. Drills are what make those controls real.
One last practical detail: how to run drills without causing disruption or overengineering the process.
How to run these drills without making your team miserable
A few small rules make resilience drills sustainable for mobile teams.
Start with tabletop drills if live testing is risky. You can still walk through the scenario, validate ownership and decision points, and improve runbooks without touching production-like systems. Keep each drill focused on one journey at a time, because testing everything at once usually means you learn nothing clearly.
Make the output consistent by using the same drill report template every time, even if it is short. Limit follow-ups on purpose. One to three improvements per drill is plenty, otherwise drills create a backlog that no one wants to own. Finally, re-run a scenario later. Repetition is how you prove that changes improved resilience, and it is how drills stop feeling like one-off events and start feeling like normal mobile operations.
Conclusion
Operational resilience under DORA does not have to be complicated. For mobile teams, the simplest approach is to focus on critical journeys, drill the failure modes that break them, and produce lightweight evidence that leads to concrete improvements.
In the next article, we will tackle the area that tends to create the most surprises in mobile: third-party risk. We will cover SDK inventory and change control, provider dependencies for critical journeys, and how to build evidence packs that are easy to review later.
Next up: DORA third-party risk for mobile AppSec: SDK governance and audit-ready evidence packs
Table of Contents
- How to use this article
- What “operational resilience” means for mobile teams
- Step 1: Pick your critical journeys, then list their dependencies
- Step 2: The drill library, the scenarios that matter most in BFSI mobile
- Step 3: What each drill should produce, the evidence that actually helps
- Step 4: Close the loop, drills should change release controls
- How to run these drills without making your team miserable
- Conclusion