Mon 15 February 2021
Announcement
Ostorlab is proud to announce the addition of a new web security scanner to its arsenal. The new scanner implements new approaches to vulnerability discovery that leverages previously identified vulnerabilities to discover similar ones.
Ostorlab Web Security Scanner was created to address a pain point that most organisations are facing; juggling multiple tools to test Mobile and Web applications with no interoperability is too much of a hassle for developers and security teams.
By providing a single tool to cover both platforms, we aim to lower the barrier to adoption. At the same time, the new detection approaches goal is to radically improve automated vulnerability discovery, and hopefully, go beyond manual testing capabilities.
The current release is still in alpha, anyone interested in giving it a try can drop us a message here.
The Problem
Ostorlab Web Security Scanner comes with novel approaches to vulnerability discovery, but before we dig into how it works, let's first clarify the issues with current vulnerability scanners.
Most security professionals will attest that SQLMap is probably the best SQL injection detection
tool available. This is largely due to its very rich database of payloads and to its coverage of a huge set of injection contexts,
like injection in a WHERE clause with a single-quote, WHERE clause with double-quote, ORDER BY contexts, HAVING contexts, SORT contexts,
MySQL contexts, Postgres contexts, Oracle contexts, you name it. Each of these injection contexts requires a specialized
payload.

For SQLMap to test a single parameter with all of these contexts, it will take few minutes to complete ... for a single parameter.
A single request can have dozens, if not hundreds of injection points, from the URL, the paths, the arguments, the headers,
the cookie values, the body parameters, and we are not even hunting for hidden parameters, like debug or trace.

Testing every page, in every input, for every vulnerability, covering every context, needs millions of requests, which requires weeks to complete.
Most scanners will finish within few hours ... at most. They achieve this by timeouting the scan or limiting their coverage. In most scanners, you can actually tweak these parameters.
This issue is not limited to backend vulnerabilities, like SQLi, code injection or template injection, but also applies to client-side vulnerabilities, like Cross Site Scripting (XSS).
XSSes also happen in different contexts on the client side, they can happen in an a tag, a div tag, in an attribute, in its
content, it can have a size limitation, a character limitation, it can be caused by injecting a specialised JSON object and
can come from different input sources.
Dynamically detecting XSS vulnerabilities requires injecting payloads, that when successful will trigger a callback. Each context requires a custom payload that results in the callback execution.
The same as for backend vulnerabilities, testing each context with a dedicated payload will result in a large number of requests that require weeks of testing.
In addition to these challenges, automating vulnerability discovery is faced with MANY other hurdles, like support for nested serialisation (a json in a base64 in a json in cookie), not leveraging previous knowledge collected in previous runs or other scans (crawls, parameters, internationalisation, brute force dictionary), or the lack of support of heavy javascript-based web applications (SPA).
Our Approach
Most vulnerability scanners can be divided into 2 parts, a set of analysis engines and a knowledge base. The engines are rather loose in their definition and can perform a different set of actions and transformations, from the most simple one, like sending an HTTP request, to the most complex ones, like taint analysis or concolic execution.
The knowledge base is then used to interpret the data collected by the analysis engines and report vulnerable behavior. Powerful detection requires both powerful engines, but most importantly a rich knowledge base.
Building knowledge bases in all vulnerability scanners is a complex, tedious, and manual process. However, the scale at which new vulnerabilities are reported, new frameworks (Vue.js, Hotwire, Svelte ...), new programming languages (Julia, Scala, Rust ...), new template engines, new backend solutions and new query languages emerge, have made the manual approach not scalable AT ALL.
While some projects have made the attempt of scaling knowledge base created through crowdsourcing, it remains a very much unsolved problem.
For Automated Vulnerability Discovery to scale, we need an Automated Way to build Vulnerability Knowledge Bases.
Backend Vulnerabilities
Our approach to address this issue comes in two flavors.
The first approach addresses backend vulnerabilities that affect "smart components", for instance a SQL database, a template engine, a shell interpreter or even an arbitrary object deserialiser.
These components typically accept a string or arbitrary bytes that result in an injection, altering the expected behavior of the application to cause harm.
When a security researcher tests for these classes of vulnerabilities, he typically starts with a very simple set of payloads to detect
weird behavior, like adding a single quote ', then two single quote '', then dividing by 0, or by (1-1). The goal is to detect
any unexpected behavior, like 500 status code or an empty response.
The tester will then use more elaborate payloads to narrow down on a class or classes of vulnerabilities, and it is at this stage that the tester's experience plays an important role to know what payloads to test, and what conclusions to draw.

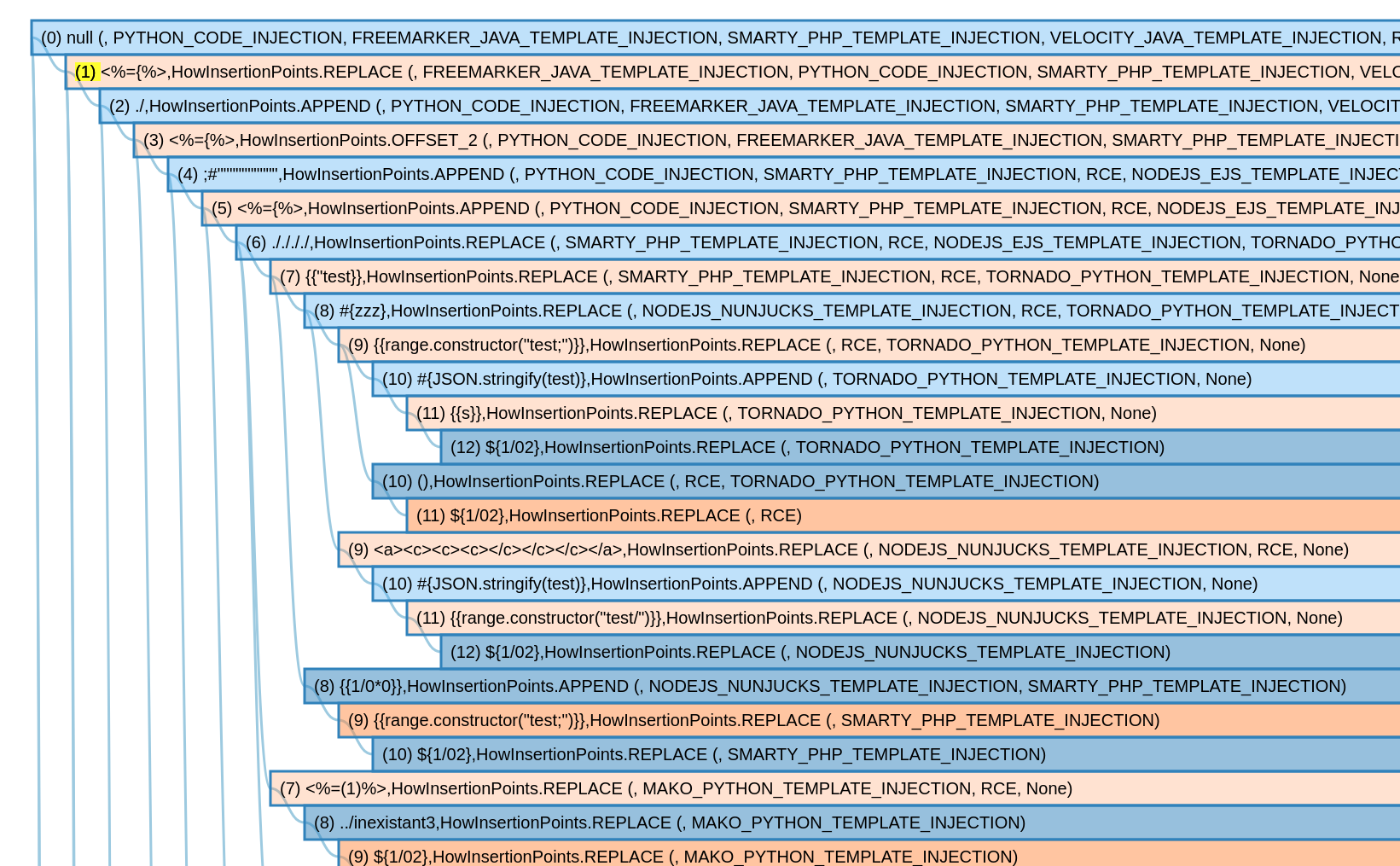
Ostorlab reproduces the same approach, instead of injecting a single elaborate payload, we inject a series of small
payloads, the responses to these payloads are then used to decide what test cases should follow. All of these payloads
compose a very large tree, with each node, we collect features from the response, like the status code, the size of
the page, the number of script tags or a tag, etc.
The goal of each test is to filter out noisy features, and if the application is vulnerable, a set of features will showcase a variation unique to a vulnerability class context.
Writing these testing trees is however a much harder task than forging a fully-featured payload, as we need to reason across previous test cases and anticipate how false positives may arise.
Automating this task is however possible, all we need to do is create a large set of vulnerable and non-vulnerable applications, tag the vulnerable one with their vulnerability class, run hundreds of thousands of payloads on all test cases and construct the testing tree using algorithms similar to decision tree generation algorithms.
The outcome is a compressed testing tree composed of thousands of nodes:

The advantage of this approach is that in the simplest case, like a static page, we only need to send dozens of payloads (vs. millions) to exclude a parameter from being vulnerable. At the same time, if the application is vulnerable, we only need to send hundreds of payloads to confirm the application is vulnerable, as the test will narrow down into a branch of the tree.
The other advantage is increasing coverage, the testing tree is only as good as our test-bed, false positives and false negatives can be addressed by adding the relevant test case and regenerating the tree, which still takes days to compute.
This mix allows us to scale both in coverage and in testing.
XSS
The 2nd approach affects the most common class of vulnerabilities, Cross Site Scripting (XSS).
Ostorlab XSS detection addresses the same challenge, but doesn't come with a radically different approach. It builds on existing work in that space, which is polyglot payloads.
Polyglot payloads are handcrafted strings that triy to compress as much target context as possible in a single payload. You can find online great publications on the topic, with competitions and a list of good payloads to use for testing.
The problem however is that some contexts are incompatible, so you absolutely need more than one, and almost every template engine that can introduce an XSS is never covered by these payloads. Javascript mobile frameworks like Cordova and Ionic come with their own list of contexts and there are no public payloads covering these contexts efficiently.
Handcrafting efficient polyglot payloads for each context is tedious, complex, and hard work.
To address these challenges, Ostorlab creates a multitude of highly optimized polyglot payloads using genetic algorithms. The resulting payloads outperform all the publicly available ones without compromising on scalability.
Genetic Algorithms are inspired by the process of natural selection that belongs to the larger class of evolutionary algorithms (EA). Genetic algorithms are commonly used to generate high-quality solutions to optimization and search problems by relying on biologically inspired operators such as mutation, crossover and selection.
Genetic Algorithms are simple to implement, they are composed of repeatable phases that stop either after finding a solution, or after a fixed number of iterations. The implementation for our problem looks as follows:

- 1st Phase, the Population: Each iteration starts with a population. The initial population in our case is a list of payloads that cover every context in our test bed. Multiple experiments were done using simple small payloads, others used high performing payloads added to the mix.
- 2nd Phase, the Evaluation: this phase consists of testing each payload on the test bed and listing for each the covered test cases.
- 3rd Phase, the Selection: consists of finding best performing payloads. This can be done using a different selection criteria, like number of covered context, size of payload, weighted ratio of context per size, etc.
- 4th Phase, the Mutation and Crossover: consists of generating a new population from the existing ones. These are a set of transformations like token injection, character flips, truncation, partial concatenation, etc.
To find best performing payloads, multiple experiments were done to find the right mix (or hyperparameters as some like to call them). For instance, using high performing payloads in the initial population results in fast coverage to high performing solutions, but quickly stagnates at a local maxima. Using small payloads however results in slow convergence but also creates unique and unexpected solutions.
The resulting payloads contained some unexpected patterns that uses undocumented behavior in browser rending engines and also showed promising results in bypassing XSS filters.
Future
Ostorlab Scanner addresses other issues, like nested serialisation detection and Single Page Application (SPA) crawling. The team behind it is actively working on adding new features, like Javascript taint analysis, postMessage XSS detection.
Ostorlab is also focusing on leveraging data collected from previous scans and other scans to enhance future results. Ostorlab is trying to get smarter with every scan run.
The current release is still in alpha, anyone interested in giving it a try can drop us a message here.
Tags:
web