
Mon 08 June 2026
Why PR Review Is a Good AI Problem
Somewhere along the way, our AI pull request reviewer stopped feeling like an experiment.
It became part of the review workflow.
Engineers disagreed with it, ignored it, and occasionally thanked it. One engineer even replied with a kiss emoji after it approved a pull request.
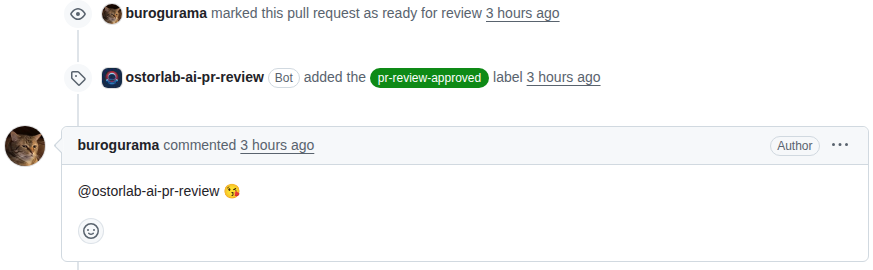
Those interactions were useful to see, not because the reviewer was always right, but because they showed what happens when AI feedback becomes part of an engineering workflow.
The question is no longer just whether the system can find issues.
It is whether engineers are willing to trust what it says.
Our first version failed.
We did not shut it down because it missed issues.
We shut it down because it found too many issues that did not exist.
That distinction matters. Most conversations about AI code review focus on coverage: how many bugs a system can find, how many vulnerabilities it can detect, or how many comments it can generate. In practice, the metric that mattered most to us was not coverage. It was trust.
Pull request review is a natural place to apply AI. Senior engineers spend a meaningful amount of time identifying recurring patterns, enforcing conventions, spotting unsafe assumptions, checking edge cases, and asking whether a change fits the rest of the system. Some of that work requires deep architectural judgment. But a large portion is repetitive and mechanical.
Those repetitive checks are exactly where AI can help.
The challenge is that code review is not just about finding problems. It is about finding the right problems, explaining them clearly, and doing so with enough precision that engineers are willing to act on the feedback.
A noisy reviewer is worse than no reviewer. A human engineer can ignore silence. They cannot ignore a plausible but incorrect comment without spending time proving that it is wrong.
That was the lesson we learned the hard way.
Our First Attempt
Our first version had a simple goal: review pull requests before a human reviewer stepped in and catch common issues early.
At the time, this felt like a practical and high-impact use case. Pull request reviews had become a bottleneck. Senior engineers were spending too much time on repetitive feedback, and review queues were slowing down development across the team.
The goal was never to replace reviewers. It was to reduce the mechanical part of the review process so engineers could spend more time on architecture, security impact, and business logic.
The first version ran automatically when a pull request was opened or updated. It collected the diff, gathered the changed files and limited surrounding context, sent that information to a language model, and posted review comments back to the pull request.
The workflow was intentionally simple:
- A pull request event triggered the reviewer.
- The system extracted the diff and changed files.
- The model reviewed the change using a fixed prompt.
- Generated findings were converted into pull request comments.
- Engineers reviewed those comments alongside human feedback.
The simplicity made the system easy to build, but it also became its biggest weakness. The agent could see what changed, but it often could not see enough of the surrounding system to understand whether a finding was actually valid.
On paper, the hypothesis was reasonable. If an AI reviewer could catch common issues before a pull request reached a senior engineer, reviewers could spend less time repeating the same feedback and more time discussing design decisions.
In practice, the system produced comments that sounded useful but were often wrong.
The Failure Mode: Plausible but Incorrect Feedback
The first version did not fail in an obvious way.
It did not post nonsensical comments. It did not misunderstand every pull request. It did not produce obviously broken recommendations.
The problem was more subtle: many comments were plausible enough that engineers felt obligated to investigate them, but incorrect enough that the investigation often wasted time.
Some examples were minor but irritating. The agent occasionally recommended style changes that conflicted with our own conventions, such as suggesting snake_case test names in a codebase that consistently used camelCase.
Some comments were more disruptive. In one case, the agent flagged code that had already been fixed elsewhere in the same pull request. In another, it recommended adding integration tests that required a browser environment, even though our CI environment did not support browser-based execution.
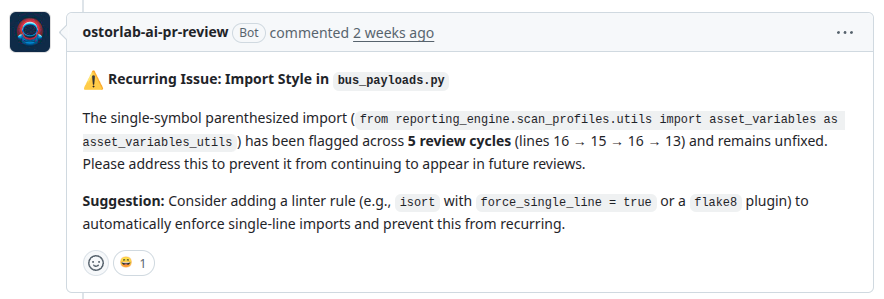
We also saw duplicate comments appear on the same pull request. The agent would identify the same perceived issue more than once and post multiple variations of the same feedback. Even when the underlying observation was valid, repetition made the review feel noisy.
The most frustrating comments were the ones that looked reasonable at first glance. For example, the agent might suggest broader exception handling without understanding that the narrower exception type was intentional. Or it might recommend a refactor that was technically valid but inconsistent with nearby code.
A bad AI review comment has a cost. Someone has to read it, understand it, check whether it applies, inspect the surrounding code, and decide whether to act on it. If the comment is wrong, all of that time is wasted.
Over time, engineers stopped treating the agent as a helpful reviewer and started treating it as another source of review noise.
At that point, the project was no longer helping.
So we turned it off.
The Real Lesson: False Positives Are Worse Than Misses
The most important lesson from the first version was that false positives are often more damaging than missed findings.
A reviewer that occasionally misses an issue can still be useful. A reviewer that repeatedly raises incorrect issues creates work for everyone else.
This is especially true in code review because review comments interrupt an engineer’s flow. A comment is not just text. It is a request for attention. It asks the author to stop, inspect the code, reason about the issue, and decide whether a change is necessary.
If that request turns out to be wrong too often, trust erodes quickly.
Once trust is lost, even correct comments become less valuable. Engineers start verifying everything. They read the agent’s feedback defensively. They assume it is probably wrong until proven otherwise.
That changes the role of the tool. Instead of reducing review burden, it increases it.
For AI code review, precision matters more than volume. Ten comments are not better than one comment if nine of them require manual dismissal. A good review agent should be comfortable staying silent.
That became the guiding principle for the second version.
Why Code Review Needs More Context Than a Diff
Our first version treated pull request review mostly as a diff-analysis problem. That was a mistake.
Experienced reviewers do not evaluate a change by looking only at the modified lines. They use a much broader set of context:
- Existing patterns in the surrounding code
- Project-specific naming and testing conventions
- Dependency behavior
- Runtime assumptions
- CI limitations
- Security boundaries
- Previous design decisions
- Business logic and product intent
- Whether a similar problem has already been solved elsewhere
A change that looks suspicious in isolation may be correct when viewed in the full system. The opposite is also true: a change that looks harmless in a diff may introduce a bug because of behavior in another file, service, or execution path.
This context gap explained many of the first version’s failures.
The model was often not wrong because it lacked language ability. It was wrong because it lacked enough information. When the system could not see the relevant context, it guessed. And when it guessed, it sometimes produced confident but incorrect feedback.
The problem was not only the model.
The problem was the architecture around the model.
Why We Revisited the Problem
We eventually revisited AI pull request review because the original problem had not gone away.
Senior engineers were still spending time on repetitive review tasks. Many of those tasks were important, but they did not always require senior-level judgment. We still believed there was value in catching mechanical issues earlier, as long as we could avoid creating noise.
At the same time, the technology had improved.
Newer models were better at understanding code, following constraints, and reasoning through implementation details. Larger context windows made it possible to provide more repository context instead of forcing the model to work from a narrow diff. Agent patterns had also matured: instead of relying on a single prompt, systems could retrieve information, inspect files, call tools, and structure their work around specific review objectives.
That changed our approach.
We were no longer trying to build a generic reviewer that commented on everything it noticed. We were trying to build a conservative review system that focused on high-confidence, high-signal findings.
The question changed from:
How many issues can the agent find?
to:
Which issues should the agent be allowed to comment on?
That shift made the second version much better.
What Changed in the Architecture
The current system did not come from a single breakthrough. It came from several iterations around one core idea: the reviewer needs context before it earns the right to comment.
Our early experiments used CrewAI to coordinate review behavior. That approach was promising, but the output was not consistently reliable enough for pull request review. We then moved to a simpler Pydantic-based workflow that gave us more structure and more control over the review pipeline. That improved consistency, but the system still misunderstood code when the relevant context was missing.
The next iteration moved toward a tool-based architecture.
Instead of asking the model to review a pull request from a fixed prompt, the system can now gather additional information as needed. It can inspect related files, look at nearby implementations, retrieve relevant conventions, and narrow its analysis to specific review tasks.
At a high level, the flow looks like this:
-
Pull request event received
The system starts when a pull request is opened or updated. -
Diff and changed files parsed
The reviewer identifies what changed and which files are affected. -
Review objectives selected
Instead of performing an open-ended review, the system focuses on specific categories of issues. -
Relevant context retrieved
The agent gathers surrounding code, related functions, tests, configuration files, and patterns from the repository. -
Targeted analysis performed
The system checks for concrete problems such as missing cleanup, unhandled exceptions, unsafe assumptions, or state changes that are not persisted. -
Findings filtered by confidence
Low-confidence observations are suppressed rather than posted. -
Comments generated conservatively
Only findings that are specific, actionable, and tied to the pull request are surfaced.
This architecture made the system more useful because it reduced guessing.
The reviewer became less like a chatbot reacting to a diff and more like a specialized engineering tool with a narrow mandate.
Context Gathering Became the Most Important Feature
The biggest improvement came from giving the system better context.
Our first version saw the pull request but often missed the surrounding implementation. The newer version can retrieve information that helps answer questions like:
- Is this pattern already used elsewhere in the repository?
- Is the suggested change consistent with nearby code?
- Does this function have callers that rely on the current behavior?
- Are there tests covering this path?
- Is this exception handling intentional?
- Does the code depend on a configuration value or runtime assumption?
- Is the issue already handled in another part of the same pull request?
This matters because many bad review comments come from incomplete visibility.
For example, if the agent sees a directory write, it may suggest checking that the directory exists. That can be useful. But if setup code already creates the directory before the function is called, the comment becomes noise.
The difference between a useful finding and a false positive is often one or two files of context.
Retrieval does not solve every problem, but it dramatically reduces the number of cases where the model has to infer behavior from a partial view.
We Stopped Optimizing for Comment Count
One of the most important changes was making the system more conservative.
The first version implicitly rewarded finding things. The second version rewards being useful.
That required a different output philosophy. The reviewer should not comment just because something might be improved. It should comment when there is a concrete issue, enough supporting context, and a clear action the author can take.
A stylistic suggestion is usually not enough. A broad refactor suggestion is usually not enough. A possible issue that depends on unknown business intent is usually not enough.
The system is now designed to prefer silence when confidence is low.
This was a difficult but necessary change. Many AI systems feel more impressive when they produce more output. Code review is the opposite. A review agent that comments less often but is usually right is far more valuable than one that comments on every possible concern.
Trust is built through restraint.
Confidence Thresholds and Comment Quality
We also started treating uncertainty as a first-class part of the system.
Before a finding is posted, the reviewer considers whether the issue is specific, actionable, and supported by the available context. A good comment should usually meet several criteria:
- It points to a concrete location in the change.
- It explains the risk clearly.
- It avoids vague language.
- It does not depend on assumptions the agent cannot verify.
- It does not conflict with visible repository conventions.
- It suggests a practical fix or next step.
- It is important enough to interrupt the author.
This filtering matters because technically correct comments can still be unhelpful.
For example, suggesting a refactor may be reasonable in isolation, but not worth posting if the code is clear, consistent with nearby patterns, and unrelated to the purpose of the pull request. Similarly, recommending broader exception handling may sound safer, but it can hide useful failure modes and make debugging harder.
The reviewer should not behave like a linter with opinions. It should behave like a careful assistant that understands the cost of every comment it posts.
What the Current Version Catches Well
The current version performs best on repetitive, mechanical issues where the expected behavior can be verified from code.
These are the kinds of findings that often matter but do not always require deep business context. They are also the types of issues that senior engineers repeatedly catch during manual review.
The system has been useful for identifying problems such as:
- Unhandled exceptions that could cause crashes
- Resource leaks hidden behind early returns
- State changes that are computed but never persisted
- Dead code left behind after refactors
- Missing setup steps, such as writing to directories that may not exist
- Inconsistent cleanup behavior across success and failure paths
- Unsafe assumptions around file, process, or network operations
- Race conditions in narrow, concrete scenarios
One particularly useful finding was a real time-of-check to time-of-use issue. The code checked that a condition was true, then performed an operation later under the assumption that the condition had not changed. That kind of issue is easy to miss in review because the relevant lines may look reasonable individually. The agent was able to connect the sequence and flag the risk.
This is where AI review currently feels most valuable for us: not as an architect, but as a tireless reviewer for mechanical correctness.
It helps remove some of the repetitive work from the critical review path so human reviewers can focus on higher-level judgment.
What It Still Misses
The system is better than the first version, but it is not close to replacing human review.
It still struggles with broad architectural reasoning, domain-specific business logic, and decisions where the most important context lives outside the repository. It can often understand how code works. Understanding why code was written that way is much harder.
Intent remains the hardest problem.
The reviewer may still suggest changes that are technically valid but not useful. It may recommend refactoring code that is already acceptable. It may suggest a more general abstraction when the current explicit implementation is easier to maintain. It may propose broader exception handling even when a narrower exception type was chosen intentionally.
For example, the system has suggested replacing specific exception handling such as:
except RuntimeError
with broader handling such as:
except Exception
In some contexts, that might be reasonable. In others, it is worse. Catching a broad exception can hide programming errors, make failures harder to debug, and weaken the guarantees that the surrounding code relies on.
The agent can evaluate implementation details, but it does not always understand design intent.
That limitation shapes how we use it. We do not want the reviewer to make broad architectural recommendations unless it has strong evidence. We want it to focus on issues where the code itself provides enough context to make the finding reliable.
How We Think About Evaluation
We no longer evaluate the reviewer by the number of comments it produces.
A high comment count is not success. In many cases, it is a warning sign.
The metrics we care about are closer to:
- How often engineers agree with the comment
- How often a comment leads to a real code change
- How many comments are dismissed as irrelevant
- How often the same issue is reported more than once
- How much time reviewers spend validating agent feedback
- Whether the agent catches repetitive issues before senior reviewers do
- Whether engineers continue to trust the tool over time
The most important signal is whether engineers treat the agent’s feedback as worth reading.
If engineers skip the comments, the system has failed, even if some of the findings are technically correct. If engineers consistently act on a small number of precise comments, the system is doing its job.
This is why we are intentionally conservative. We would rather miss a borderline issue than train engineers to ignore the reviewer.
From Internal Experiment to Platform Feature
What started as an internal experiment is now informing a broader product direction.
We are working on bringing AI-powered code review capabilities into the Ostorlab platform. Before exposing the feature externally, we wanted to use it on our own pull requests, observe where it helped, and understand where it needed guardrails.
That internal usage clarified what the feature should be.
It should not replace engineering judgment. It should not turn every pull request into a wall of AI-generated comments. It should not behave like an overconfident junior reviewer trying to prove it found something.
Instead, it should help teams catch repetitive, mechanical, and security-relevant issues earlier in the development process.
This is especially important for application security. Many security issues are cheaper to fix during code review than after deployment or during a later scan. A useful AI reviewer can complement existing AppSec workflows by identifying risky patterns closer to the point where code is written.
That does not make it a replacement for SAST, DAST, manual security review, or experienced engineers. It makes it another layer in the workflow: one focused on early, contextual, developer-facing feedback.
We have already seen interest from users asking when this capability will be available. That demand reinforces our belief that code review is becoming an important part of the application security workflow.
But usefulness matters more than speed to release. Our priority is to make the feature conservative, trustworthy, and practical before it reaches production users.
Lessons Learned
AI Reviewers Are Not Junior Engineers
A common mistake is treating AI reviewers as if they were junior developers.
They are not.
Junior engineers accumulate context over time. They ask questions. They remember previous decisions. They learn the history of a system and the preferences of a team. They develop judgment through experience.
AI systems operate differently. They are strong at pattern recognition, consistency, summarization, and repetitive analysis. They can inspect large amounts of code quickly. They can identify mechanical issues that humans may overlook.
But they do not naturally understand organizational history, product intent, or architectural tradeoffs unless those things are made available to them.
The best role for an AI reviewer is not replacement. It is assistance.
Trust Matters More Than Coverage
The most important metric is not how many findings the reviewer generates.
It is how many findings engineers trust.
A system that produces ten accurate, actionable comments is more valuable than one that produces one hundred comments requiring manual verification. Coverage matters, but only after the system has earned trust.
For code review agents, restraint is a feature. Silence is sometimes the correct output.
Context Is the Difference Between Helpful and Noisy
Many AI review failures are context failures.
A model reviewing a narrow diff may identify something that looks suspicious but is already handled elsewhere. It may recommend a convention that conflicts with the repository. It may misunderstand a test environment, runtime assumption, or architectural boundary.
Better models help, but better context matters just as much.
The reviewer needs access to the information a human reviewer would naturally use: surrounding code, related files, tests, conventions, configuration, and prior patterns.
Without that context, the system guesses. And confident guesses are dangerous in code review.
Sometimes the Right Decision Is to Stop
Our first attempt failed.
At the time, that was disappointing. Looking back, it was one of the most useful outcomes of the project.
Shutting it down forced us to understand the real problem. The issue was not simply that the model needed to be better. The issue was that our system was optimized for producing review comments rather than producing trusted review comments.
When we revisited the project, we were not starting over. We were building on the lessons from the failed version.
Not every engineering project succeeds on the first attempt. Sometimes the right decision is to stop, learn, and return when both the technology and your understanding of the problem have improved.
That is what happened here.
We still do not think AI should replace human pull request review. But we do think it can make review better when it is focused, contextual, and conservative.
The goal is not an AI reviewer that comments more.
The goal is an AI reviewer engineers actually trust.
Table of Contents
- Why PR Review Is a Good AI Problem
- Our First Attempt
- The Failure Mode: Plausible but Incorrect Feedback
- The Real Lesson: False Positives Are Worse Than Misses
- Why Code Review Needs More Context Than a Diff
- Why We Revisited the Problem
- What Changed in the Architecture
- Context Gathering Became the Most Important Feature
- We Stopped Optimizing for Comment Count
- Confidence Thresholds and Comment Quality
- What the Current Version Catches Well
- What It Still Misses
- How We Think About Evaluation
- From Internal Experiment to Platform Feature
- Lessons Learned